これは TECHSCORE Advent Calendar 2017の3日目の記事です。
はじめに
筆者は5年ほどデータ分析の仕事に関わっていますが、それまで業務アプリの開発経験しかなかったものですから、分析という仕事の進め方が分からず戸惑うことが多かったです。最近になって少しずつ分かってきた部分もあるので、過去の自分に向けた手引きを書きたいと思います。
読者の方へ。前提として、筆者の関わるデータ分析は他社からの受託あるいは共同研究の形で始まる、いわゆるアドホック分析で、データ件数的には多くて数百万程度のスモールデータです。自社データの分析や機械学習のプロダクト開発、Hadoopなどのビッグデータ処理環境においてはあてはまらない部分があるかと思いますのでご了承ください。なお分析環境としては基本的に執筆時最新のRとRStudioをPCにインストールして使用しています。
プログラマから見た分析のワークフロー
説明にあたって、プログラム開発と比較しながらデータ分析のワークフローの特徴を挙げておきます。
小さなコードの積み重ね
分析のワークフローは時に非常に複雑なものになりますが、要素分解すると、一つ一つはファイルを受け取り別のファイルを返す小さなコードにすぎません。一方で、ワークフローの複雑さは処理またはファイルの間の依存関係に現れます。ある処理の結果を参照しやすくするための置き場所や命名、ワークフローの一部を修正する際の依存関係の解析にしばしば悩まされます。
イミュータブルデータ
一般の情報システムでも、データの更新を避け追記中心に設計したり、コードレベルでも変数をなるべくイミュータブルに取り扱うのが良いと言われます。更新処理は複雑で不具合を起こしやすいというのが理由です。加えてデータ分析では、間違えたら単に結果を破棄すれば良いという安心感が得られます。
探索的だが再現性も必要
ソフトウェア開発は一度書いたコードが何度も実行されることを前提としているため、テストやリーダビリティ向上にそれなりのコストを払う動機がありますが、アドホックな分析のために書かれたコード(操作手順も含む)は一回しか実行されなかったり、失敗して破棄されることもしばしばです。分析者が未熟だったり、問題やデータの理解が不十分な場合は試行錯誤が多いこともあり、コードやファイルが散らかったり、最悪どのようにして結果が得られたのか分からなくなってしまうこともあります。また、一つ一つのコードが実験的であることから、データ分析のワークフロー全体もやってみないと分からないところがあり、探索的と呼ばれます。プロトタイピングに近いかも知れません。一方で、データサイエンスという言葉があるように、データ分析はサイエンスの一種ですから、結論にいたるまでの過程が説明でき、検証できることが求められます。再現性があるといいます。報告書の内容を書く以外の工程が全てコード化されているのが理想です。
分析ワークフローのライフサイクル
データ分析のワークフローが探索的であることから、最終成果物が得られるまでワークフローは変化し続けると想定する方がよいでしょう。ここでは変化のライフサイクルを考察します。
典型的な形
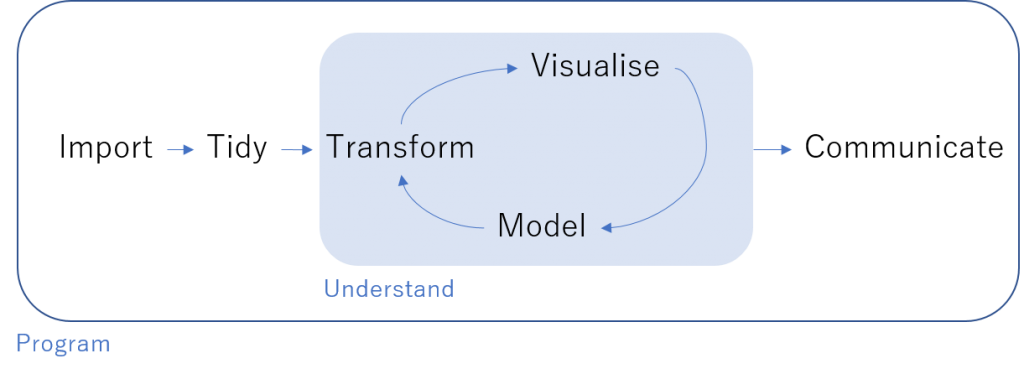
R for Data Science によると探索的な分析は上の図のように進むとされています。最終的に分析結果を伝えることを目的とし、分析対象を十分理解するまで反復型で進めていくのがポイントです。ただ、反復の過程は一本調子ではなく、いくつか進め方が変わる局面があるなと感じたのが本稿を書く動機です。
準備
R+RStudio を使う場合、まずプロジェクトディレクトリを作成し、その中にローデータであるファイルをコピーしてくるところからはじめます。大抵そのままでは分析に使えないため、何らかの加工が必要です。
Import
ファイルが月別に分かれていたり、zip圧縮されていたり、ファイルもテキスト(CSV)ではなく.xlsxで受領することもよくあること。分析環境に取り込むために多少工夫を要します。お預かりしたデータを破壊すると元に戻せませんから、バックアップとファイルを上書きしない手順がきわめて重要です。手作業が入り込みがちですが、大抵の場合Rと拡張パッケージの組み合わせで何とかなります。
Tidy
分析に必要なデータは分析の目的と手法によって変わりますが、どんな分析でも扱いやすい形式にしておくと後が楽になります。具体的には重複の削除や正規化、列名の整理をしておきます。分析の方向性が見えてない段階では、最初から1個の大きなファイルを作るのではなく、種類別にファイルを分けておいて後で結合できるようにしておく方が良いでしょう。
Visualise
ついつい先を焦って飛ばしてしまうのですが、あれこれ分析するまえにどういうデータなのかをつかんでおくのは大事です。列ごとの分布をヒストグラムなどで確認したり、クロス集計や散布図で列の間の関連性を見ておくといいでしょう。この時のコードとグラフや集計表を残しておくと、自分向けのリファレンス資料ができ有益です。近年はJupyter Notebookというツールにより、コードと実行結果とドキュメントを一枚にまとめることが簡単にできるようになりました。R+RstudioでもR notebookという形式でファイルを作ると、結果をプレビューしながら、配布可能なHTMLファイルを同時に残すことができ、大変便利です。
探索
最初から難しいことをやろうとしても、準備に時間を取られすぎたり、どこかで前提が崩れてやり直すことが多いです。単純で軽い分析手法を使ったり、データの一部を切り出すなどして、できるだけ一日以内で結果を得られるような小さな実験から手を付けるべきでしょう。
実験に必要なコードと結果は一箇所にまとまっていると管理しやすいです。失敗してもそこだけ無視すれば良いですし、条件を変えてやり直したくなったらコピーして修正できます。先ほどのJupyter Notebookを使うことができます。いちいちファイル名を考えるのも難しかったりしますから、ファイル名に日付や連番を付けてフラットに保存しておくのが良いでしょう。
これはNotebookを理解のための使い捨てプロトタイプと割り切った使い方です。
統合
ある程度理解が進んだら、最終的なアウトプットをどうするかも見えてきます。これまで場当たり的に書いていたコードを以下のように整理していきます。込み入った手順となる場合、PFDやDFDでスケッチしておくと良いでしょう。
- 共通コードを関数に切り出す
- 時間のかかる加工を行った結果を中間ファイルに書き出す
- 関連するファイルをフォルダにまとめる
- 一部のデータではなく全データにモデルを適用する
- パラメータやモデルを入れ替えて比較する
- モデルの出力結果を使って別の分析を行う
ここでは実行時間が長くなったり繰り返し作業も増えるため、対話型のNotebookは向いていません。普通のスクリプトを書いて一括実行することが多いです。複数のRスクリプトを連続実行するためにシェルスクリプトを書くこともあります。
改訂
このやり方でいけそうと思っても、残念ながら行き詰ってしまうことはあります。その他にも、途中でデータが追加されたり、報告のフィードバックを受けてワークフローを修正することがあります。複数のファイルが依存しあうワークフローを修正するのは簡単ではありません。
よくやってしまうのは、スクリプトやデータ置き場にoldフォルダを作って退避し、書き直すということですが、Git などを使うのが望ましいでしょう。また Make を使うと、一部を修正した時に依存関係を考慮して必要なファイルだけ更新することもできます。Git も Make も強力なツールですが、やりすぎのような気もして、筆者はまだまだ使いこなせていません。
まとめ
データ分析でもコードをたくさん書きますし、データ設計のスキルが役に立つのでプログラマはデータ分析の仕事に向いていると思います。人によっては完成形が見えずに試行錯誤を繰り返すような仕事の進め方に苦労するかも知れません。分析対象を理解するまで最初は小さな実験を繰り返すことを意識しましょう。
また、データ分析には再現性が重要とされます。最低限コードで手順を残すことと、ファイルをイミュータブルなものとして扱うことは習慣付けたいものです。
見通しが立たない段階では、実験単位で手順と結果をまとめ、時系列でフラットに保存しておけば良いでしょう。ある程度理解が進んで、主張したい結論から手順を逆算できるようになったら、ファイルの配置とコードを整理します。
最終成果物に得るためのコードと一時的な実験コードを区別することが、データ分析の探索的な面と、再現性を両立させるポイントだと思います。
