12.構造体
12.1.構造体とは
「intやcharなどの基本データ型を好きなように組み合わせて、新しいデータ型として扱うもの」を「構造体」と呼びます。構造体はひとつの名前だけで関連したいくつもの変数を一度にあつかうことができます。通常それらの間には密接な関係があり、構造体はそれらをひとつの名のもとに組織化するという働きをします。
例えば生徒の「学生番号」「名前」「学年」を管理したい場合、それぞれを別々に管理するよりも以下のような構造体を作成する方がすっきりとします。
struct student{
char id[20];
char name[20];
int gakunen;
};
12.2.構造体変数の宣言・初期化
構造体を使用する場合、「構造体そのものの宣言」と「変数の宣言」の2つに分かれます。 構造体そのものの宣言は前節の通りです。構造体変数の宣言は以下の通りになります。
struct student seito;
「struct (構造体名) (変数名);」の形式で宣言します。 宣言時に値を設定する事を「変数の初期化」と呼びますが、構造体の場合は以下の2通りの方法があります。
struct student seito={"20000403","Yojigen Taro",1};
struct student{
char id[20];
char name[20];
int gakunen;
}seito={"20000403","Yojigen Taro",1};
中括弧を使用して構造体のメンバ(構造体を構成する変数)全てに、値を設定しています。この方法を使用できるのは初期化のときだけで、それ以降に値を設定するには別の方法を使用しなければなりません。
12.3.メンバの参照・代入
構造体のメンバにアクセスするには「メンバ演算子」を使用します。これには2種類あり、構造体の実体が変数かポインタによって変わります。構造体が変数の場合は「.」(「ドット演算子」と一般的に呼ばれている)を使用します。以下は、student構造体変数seitoのnameメンバの値を出力するサンプルです。
struct student seito={"20000403","Yojigen Taro",1};
puts(seito.name);
「(構造体変数名).(メンバ名)」で、そのメンバにアクセスする事ができます。代入も同じように行います。
seito.gakunen=2;
printf("%d\n",seito.gakunen);
構造体の実体がポインタの場合は「->」(「アロー演算子」と一般的に呼ばれている)を使用します。 ポインタの扱いについては基本データ型のポインタの扱いと同じになります。
struct student seito={"20000403","Yojigen Taro",1};
struct student *sp=&seito;
puts(sp->name);
sp->gakunen=2;
printf("%d\n",sp->gakunen);
中括弧を使用しての代入は初期化以外の時に使用できませんが、構造体から構造体への代入はいつでも可能です。例えば以下の場合、構造体変数seitoの各メンバの値は構造体変数seito2にコピーされます。
struct student seito={"20000403","Yojigen Taro",1};
struct student seito2=seito;
(実習課題)
以下のプログラムを作成しなさい。
- ファイルからデータを読み取り、それを出力する。ファイルに書かれているデータは、社員の「名前」「年齢」および「住所」。1行に1つずつデータが書かれており、3行で1人分の社員のデータとなる。1人の社員のデータと次の社員のデータの間には空行が1つ入っているものとする。
- 読み込むデータ数は、プログラムの実行時にオプションとして指定されるものとする。ファイル内のデータ数が指定されたデータ数より少ない場合は、エラーを出力してプログラムの実行を終了する。多い場合は、指定されたデータ数分だけ読み込んで、処理を実行する。
- 出力のフォーマットは任意とする。
- ファイルから読み込む部分と、標準出力へ出力する部分はmainとは別関数にする事。
12.4.自己参照構造体
構造体を構成するメンバは基本データ型の変数だけでなく、構造体も可能です。以下の例では、syohin構造体にkakaku構造体の変数が使用されています。
struct kakaku{ /* 価格構造体 */
int genka; /* 原価 */
int baika; /* 売価 */
};
struct syohin{ /* 商品構造体 */
char *name; /* 商品名 */
struct kakaku syohin_kakaku; /* 商品価格 */
};
この構造体の入れ子には1つ制約があり、自分と同じ構造体の変数を含める事はできないことになっています。「構造体Aの中に構造体Aの変数があり、その中に構造体Aの変数があり...」と無限ループに陥ってしまうためです。しかし自分と同じ構造体へのポインタを含める事はできます。これは「自己参照構造体」と呼ばれ、さまざまなデータ構造を実現する事ができる、非常に強力な機能です。
ここではリスト構造を実現する事を考えます。リストとは下図のような数珠繋ぎのデータ構造で、添字でアクセスできる配列とは異なり、先頭から順にしかアクセス(順次アクセス)できません。しかし配列とは異なり、データの途中挿入や削除が容易にできるという利点を持っています。

ここでは社員の「名前」と「年齢」データをリスト構造で管理する事を考えます。構造体のメンバとなるのは、「名前」「年齢」およびリスト構造を実現するための「次のデータを指し示すポインタ」ということになります。以下のようになります。
struct employee{
char name[256];
int age;
struct employee *next;
};
この構造体を用いて下図のデータ構造を実現してみます。

struct employee employee1={"四次元太郎",27,null};
struct employee employee2={"四次元花子",25,null};
employee1.next=&employee2;
struct employee employee3={"四次元一",27,null};
employee2.next=&employee3;
employee1のnextにemployee2のアドレスを、employee2のnextにemployee3のアドレスを代入しています。
リスト構造はポインタの付け替えだけで、容易にデータの挿入・削除ができるのが特徴です。挿入の場合は下図のようにします。新しいデータ6を2と3の間に挿入する場合、2のnextが6を指すようにし、6のnextが3を指すように変えます。
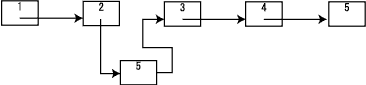
削除の場合は下図のようにします。3を削除する場合、2のnextが4を指すようにするだけで実現できます。

(実習課題)
以下のプログラムを作成しなさい。
- 標準入力から入力された社員データをリストデータで管理する。
- 入力される社員データは「名前」「年齢」の2つ。データは年齢順にソートされるものとする。
- プログラムを実行すると社員データの「挿入」「表示」「削除」「終了」の3つのコマンドを選択できる。コマンドの選択は番号の入力で良い。
- 「挿入」コマンドを選択すると、データの入力を促す画面が表示される。データを入力すると適当な箇所にデータが挿入される。
- 「表示」コマンドを選択すると、これまでに入力されたデータの一覧が表示される。
- 「削除」コマンドを選択すると、削除するデータの順番の入力を促す画面が表示される。順番を入力すると該当箇所のデータが削除される。
- 「終了」コマンドを選択すると、プログラムの実行が終了する。
- (ヒント)無限ループを使用する。ループの先頭でコマンドの選択を実行し、その後コマンドごとの処理を行う。「終了」が選択された場合はループを抜けてプログラムを終了する。
- (ヒント)リストの先頭のデータを指し示す特別なポインタが必要。リストの最後は「null」で表現する。
- (ヒント)構造体の動的な作成には「malloc」を使用。「sizeof(struct employee)」でemployee構造体のサイズがわかる。
