7. 国際化対応
2006.03.14 株式会社四次元データ 鈴木 圭
- 7.1. 新しいロケールのサポート
- 7.2. 和暦のサポート
- 7.3. Locale Sensitive Services SPI
- 7.4. Unicode 正規化 API
- 7.5. IDN のサポート
- 7.6. リソース・バンドルの強化
Mustang における国際化対応では、和暦ロケールを含む新しいロケールのサポートや、Unicode 正規化 API の追加、リソース・バンドルの強化、国際化ドメイン名の対応などが行われました。和暦ロケールのサポートによって DateFormat クラスの format/parse メソッドで "平成元年1月1日" などの和暦で書かれた文字列にフォーマット/パースすることが可能なったことや、Unicode 正規化 API の導入によって今まで Java ではサポートされていなかった Unicode 文字列の正規化を行うことができるようなるなど、着実に国際化機能の強化が行われています。
7.1. 新しいロケールのサポート
Mustang では以下に示すロケールが新しくサポートされました:
| 言語 | 国 | ロケール ID |
|---|---|---|
| 日本語(和暦) | 日本 | ja_JP_JP |
| 中国語 (簡体字) | シンガポール | zh_SG |
| 英語 | マルタ | en_MT |
| 英語 | フィリピン | en_PH |
| 英語 | シンガポール | en_SG |
| ギリシャ語 | キプロス | el_CY |
| インドネシア語 | インドネシア | id_ID |
| アイルランド語 | アイルランド | ga_IE |
| マレー語 | マレーシア | ms_MY |
| マルタ語 | マルタ | mt_MT |
| ポルトガル語 | ブラジル | pt_BR |
| ポルトガル語 | ポルトガル | pt_PT |
| スペイン語 | アメリカ | es_US |
新しく追加されたこれらのロケールは、今までとは異なり CLDR(Common Locale Data Repository)のデータを使用します(既存のロケールに関しては、過去のバージョンとの互換性を保つため CLDR の導入は行われませんでした)。CLDR とは Unicode コンソーシアムによって提供されるロケール・データの共通リポジトリです。今までは OS やソフトウェアごとに独自にロケール・データを持つことで国際化対応を行っていましたが、そのサポート具合にはばらつきがあり、互換性もありませんでした。そこで、ロケール・データの標準を提供する目的で登場したものが CLDR です。
色々なロケールが新しくサポートされましたが、中でも和暦ロケール(ja_JP_JP)がサポートされたことは注目すべきでしょう。
7.2. 和暦のサポート
和暦ロケールの作成は java.util.Locale クラスの三引数のコンストラクタ Locale(String language, String country, String variant) を用いて作成します:
// 和暦ロケールの作成.
Locale japaneseImperialLocale = new Locale("ja", "JP", "JP");
この和暦ロケールを用いて、和暦カレンダーの利用や日付のフォーマットを行うことができます。
和暦カレンダー
java.util.Calendar クラスの getInstance メソッドに和暦ロケールを渡すことで、和暦カレンダーを取得することができます:
// 和暦カレンダーの取得.
Calendar japaneseImperialCalendar = Calendar.getInstance(new Locale("ja", "JP", "JP"));
Calendar#get(int field) メソッドに Calendar.ERA を渡すことで、その Calendar インスタンスの表す日付の元号を得ることができます。Calendar#get メソッドの戻り値と元号の対応は以下のようになっています:
| Calendar#get の戻り値 | 対応する元号 |
|---|---|
| 0 | 未対応(西暦) |
| 1 | 明治 |
| 2 | 大正 |
| 3 | 昭和 |
| 4 | 平成 |
以下に現在日時から元号を取得するコードを示します:
// Calendar オブジェクトを作成し、現在の日付を設定する.
Calendar calendar = Calendar.getInstance(new Locale("ja", "JP", "JP"));
calendar.setTime(new Date());
// 元号を得る.
String[] eraNames = { "未対応(西暦)", "明治", "大正", "昭和", "平成" };
String eraName = eraNames[calendar.get(Calendar.ERA)];
System.out.println(calendar.getTime() + " の元号は「" + eraName + "」です.");
これを実行すると以下のような出力が得られます:
Sat Aug 12 21:13:17 JST 2006 の元号は「平成」です.
DateFormat によるフォーマット/パース
java.text.DateFormat クラスを用いると、Date インスタンスを和暦表現の文字列にフォーマットすることや、パースすることができます。和暦に対応した DateFormat インスタンスを得るには、DateFormat#getDateInstance メソッドを用いるか、派生クラスである java.text.SimpleDateFormat を直接インスタンス化します。
以下に DateFormat を用いて Date のフォーマット及びフォーマットした文字列のパースを行う例を示します:
// 和暦ロケールの DateFormat を取得.
DateFormat dateFormat =
DateFormat.getDateInstance(DateFormat.FULL, new Locale("ja", "JP", "JP"));
// 現在の日付を文字列にフォーマット.
String formatted = dateFormat.format(new Date());
System.out.println(formatted);
// フォーマットした文字列をパース.
Date parsed = dateFormat.parse(formatted);
System.out.println(parsed);
これを実行すると以下のような出力が得られます:
平成18年8月12日 Sat Aug 12 00:00:00 JST 2006
7.3. Locale Sensitive Services SPI
Mustang では Java ランタイムがサポートしていないロケール対応するために Locale Sensitive Services SPI が導入されました。Locale Sensitive Services SPI の SPI は「Service Provider Interface」のことであり、ロケールに依存したクラスの実装を提供することができます。
Locale Sensitive Services SPI によってロケール固有の実装を提供することができるクラスは以下の通りです:
- java.util.Locale クラスのための言語名、国名
- java.util.TimeZone クラスのためのタイム・ゾーン名
- java.util.Currency クラスのためのシンボル
- java.text.BreakIterator オブジェクト
- java.text.Collator オブジェクト
- java.text.DateFormat オブジェクト
- java.text.NumberFormat オブジェクト
- java.text.DateFormatSymbols オブジェクト
- java.text.DecimalFormatSymbol オブジェクト
これらにロケール依存の実装を提供するためのサービス・プロバイダの抽象クラスは java.util.spi 及び java.text.spi パッケージに含まれています。Java ランタイムは多くのロケールをサポートしていますが、Java ランタイムがサポートしていないロケールをアプリケーションとしてサポートしなければならない場合には Locale Sensitive Services SPI を利用します。
7.4. Unicode 正規化 API
Unicode 文字列の正規化を行うために java.text.Normalizer クラスが追加されました。Normalizer クラスは文字シーケンスを正規化するための normalize(CharSequence, Normalizer.Form) メソッドと、文字シーケンスが特定の正規化形式で正規化されていることを判定する isNormalized(CharSequence, Normalizer.Form) メソッドを持ちます。正規化形式の種類は列挙型 Normalizer.Form によって表されます。
ここで、Unicode 文字列の正規化について簡単に説明します。Unicode では「ё」のようなアクセント付き文字や「だ」などの濁点/半濁点を持つ文字を合成文字として扱います。これらの合成文字は、一般的なものは合成済み文字として事前定義されていますが、任意の文字を合成文字とするための動的合成という方法もあります。そして、合成済み文字として定義されている文字でも動的合成によって表すこともできます。このため、同じ文字を表していてもバイト列としては異なるという場合があり、文字列の検索や比較を行うときに、検索に見つかるべき文字列が見つからないなどの不都合が発生します。そこで文字列のバイナリ・レベルでの表現形式を統一する「正規化」が必要となります。
Unicode の正規化形式については Unicode Standard Annex #15 Unicode Normalization Forms で定義されています。正規化の形式は一種類ではなく、以下に示す形式が定義されています:
| 名称 | 分解変換 | 正規合成 |
|---|---|---|
| Normalization Form D(NFD) | 正規分解 | 行わない |
| Normalization Form C(NFC) | 正規分解 | 行う |
| Normalization Form KD(NFKD) | 互換分解 | 行わない |
| Normalization Form KC(NFKC) | 互換分解 | 行う |
この表に「分解変換」という項目がありますが、「分解変換」とは合成文字を基底文字(「ё」の場合は「e」)と結合文字(「ё」の場合は「¨」)の組み合わせに分解する処理のことを言います。分解の仕方には「正規分解」という合成文字を等価な文字列に置き換えるだけのものと、「互換分解」という元の文字を等価な文字列だけではなく互換性のある文字列にも置き換えるものがあります。互換分解が行われる身近な例としては、いわゆる半角文字が全角文字に変換されることが挙げられます。
Normalization Form C(NFC)及び Normalization Form KC(NFKC)に関しては、「分解変換」が行われた後に「正規合成」と呼ばれる処理が行われます。正規合成とは合成済み文字に変換可能な「基底文字+結合文字」の組み合わせを合成済み文字に変換する処理のことで、「正規分解」の反対の処理になります。
これらの正規化形式に対応する列挙型 Normalizer.Form の値は以下の通りです:
| 正規化形式 | 対応する Normalizer.Form の値 |
|---|---|
| NFD | Normalizer.Form.NFD |
| NFC | Normalizer.Form.NFC |
| NFKD | Normalizer.Form.NFKD |
| NFKC | Normalizer.Form.NFKC |
正規化形式の違いを比較する
先に述べたように、同じ Unicode 文字列であっても正規化形式が異なれば検索や比較を正しく行うことができません。ここでは半角カタカナの「ガ」という文字列を例に正規化形式の違いを比較します。以下の図を見てください:
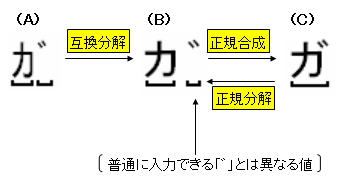
これは「ガ」という文字列に対して分解や合成を行ったときの値の変化を表したものです。図中の(A)を基準に分解や合成でどのように値が変化するのか注目してください。「ガ」という文字列を互換分解すると「カ」の部分が全角カタカナの「カ」に、「゛」の部分も濁点を表す別の値(普通に入力できる「゛」とは違う値)に変換され、結果として(B)の値になります。そして(B)の値を正規合成すると(C)の値、つまり全角カタカナの「ガ」になります。(A)からみると(B)、(C)はそれぞれ NFKD、NFKC 形式で正規化した文字列ということです。実際にこの変換を行うプログラムは以下のようになります:
import java.text.Normalizer;
import java.text.Normalizer.Form;
public class Main
{
public static void main(String[] arguments)
{
String string = "ガ";
// 元文字列
System.out.println(string);
// (A) を互換分解 → (B) の状態になる
string = Normalizer.normalize(string, Form.NFKD);
System.out.println(string);
// (B) を正規分解+正規合成 → (C) の状態になる
// (補足:(B) は分解済みなので正規分解しても値は変わらない)
string = Normalizer.normalize(string, Form.NFC);
System.out.println(string);
// (C) を正規分解 → (B) の状態になる
string = Normalizer.normalize(string, Form.NFD);
System.out.println(string);
}
}
出力結果:
ガ カ? ガ カ?
出力結果に「?」が含まれていますが、これは先の図の(B)に含まれる濁点に相当する値に対応するフォントが無いためです。それを考慮すると、先の図で示した変換が行われていることが確認できます。
Unicode 正規化は Unicode 文字列を扱う上で不可欠なものですので、正規化はその形式の違いを正しく理解して行う必要があります。特に互換分解が行われる NFKD 及び NFKC は、元の文字列と(互換性はあるが)等価でない値に変換されることに注意する必要があります。
7.5. IDN のサポート
IDN(Internationalized Domain Names)のサポートが行われました。IDN とは国際化ドメイン名とも呼ばれ、ドメイン名に非 ASCII 文字を使用することができます。このために java.net.IDN クラスが追加されました。IDN クラスには ACE 変換(ASCII Compatible Encoding:非 ASCII 文字を含む IDN を既存の DNS サーバでも運用できるようにするために ASCII 文字だけの表現にするための変換)及び復元を行うメソッドなどが含まれています。
以下に IDN クラスを用いて ACE 変換及び復元を行う例を示します:
import java.net.IDN;
public class InternationalizedDomainNameMain
{
public static void main(String[] arguments)
{
String ascii = IDN.toASCII("http://www.日本語.example");
System.out.println(ascii);
String unicode = IDN.toUnicode(ascii);
System.out.println(unicode);
}
}
出力例:
http://www.xn--wgv71a119e.example http://www.日本語.example
7.6. リソース・バンドルの強化
Mustang ではリソース・バンドル機能の強化が行われました。これによりキャッシュの制御や読み込むファイルの種類の指定、アプリケーションを再起動せずにリソース・バンドルの再読み込みを行うことなどが可能となります。新しく追加された ResourceBundle.Control というクラスがリソース・バンドルの制御に関する情報を提供する役割を持ち、その情報を元に ResourceBundle クラスが適切にリソース・バンドルの読み込みなどを行います。
このために ResourceBundle の getBundle メソッドに ResourceBundle.Control を受け取るオーバーロードが追加されました。これらのメソッドを利用することで、ResourceBundle と ResourceBundle.Control を協調させることができます。ResourceBundle.Control のインスタンスは、ResourceBundle.Control の static メソッドを利用するか、独自にサブクラスを作成します。
ResourceBundle.Control クラス
ResourceBundle.Control クラスのメソッドは、主に ResourceBundle クラスによって利用されます。ResourceBundle クラスは ResourceBundle.Control からの情報を元に、読み込むファイルの決定やキャッシュの制御を行います。
以下に ResourceBundle.Control クラスの主なメソッドを示します:
- Locale getFallbackLocale(String baseName, Locale locale)
- 引数に渡される baseName と locale の組み合わせに対応するリソース・バンドルが見つからなかった場合に呼び出されます。戻り値として代替となるロケールを返します。代替が存在しない場合は null を返します。 - List<String> getFormats(String baseName)
- 読み込むを許可するリソース・バンドルの種類を返します。static フィールドにはデフォルトを表す FORMAT_DEFAULT、.properties ファイルを表す FORMAT_PROPERTIES、.class ファイルを表す FORMAT_CLASS が定義されています。 - long getTimeToLive(String baseName, Locale locale)
- 読み込んだリソース・バンドルの TTL(Time-To-Live)をミリ秒単位で返します。アプリケーションの再起動をすることなく更新したリソース・バンドルの値を再読み込みさせたい場合にオーバーライドします。static フィールドにはキャッシュを無効にすることを意味する TTL_DONT_CACHE 及びキャッシュの期限が無限であることを意味する TTL_NO_EXPIRATION_CONTROL が定義されているので、必要であればこれらの値を返します。 - String toBundleName(String baseName, Locale locale)
- 与えられた基底名とロケールに対応するバンドル名を返します。デフォルトでは resource_jp_JP_JP のような名前を返しますが、標準とはことなるバンドル名を使用したい場合にメソッドをオーバーライドします。
ResourceBundle をより細かく制御したい場合は、ResourceBundle.Control のサブクラスを作成し、必要なメソッドをオーバーライドします。
また、ResourceBundle.Control インスタンスを得るための static メソッドには以下のものがあります:
- static ResourceBundle.Control getControl(List<String> formats)
- getFormats メソッドの戻り値に formats に指定したフォーマットを返す ResourceBundle.Control インスタンスを返します。 - static ResourceBundle.Control getNoFallbackControl(List<String> formats)
- getControl と同じですが、getFallbackLocale メソッドの戻り値として null を返す ResourceBundle.Control インスタンスを返します。
どちらのメソッドも、引数として getFormats メソッドの返すフォーマットを指定しますが、これには ResourceBundle.Control の public static フィールドである FORMAT_PROPERTIES、FORMAT_CLASS、FORMAT_DEFAULT のいずれかを指定することができます。
サンプル・プログラム
以下にアプリケーションを再起動することなくリソース・バンドルが再読み込みされることを確認するためのプログラムを示します:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Locale;
import java.util.ResourceBundle;
public class ResourceBundleMain
{
public static void main(String[] arguments) throws IOException
{
BufferedReader reader =
new BufferedReader(new InputStreamReader(System.in));
for(;;) {
System.out.print("Press [Enter] or [Ctrl]+[Z] ...");
String line = reader.readLine();
if(line == null) { break; }
ResourceBundle resource =
ResourceBundle.getBundle("resource", new NonCacheResourceBundleControl());
String message = resource.getString("message");
System.out.format("message=%s\n", message);
}
}
private static class NonCacheResourceBundleControl extends ResourceBundle.Control
{
@Override
public long getTimeToLive(String baseName, Locale locale) {
// キャッシュは無効.
return TTL_DONT_CACHE;
}
}
}
# resource.properties の内容 message=Hello
このプログラムではキャッシュを無効にするため、NoCacheResourceBundleControl という名前の ResourceBundle.Control のサブクラスを作成し、getTimeToLive メソッドで TTL_DONT_CACHE を返すようにしています。そして、ResourceBundle#getBundle メソッドに NoCacheResourceBundleControl を渡しています。
プログラムを実行すると、[Enter] キーが押されるたびにリソース・バンドルから "message" キーに対応する値を取得して表示します([Ctrl]+[Z] で終了します)。試しにリソース・バンドルの内容を変更してから [Enter] キーを押すと、更新された新しい値が取得されることが確認できます。
まとめ
今回は Mustang の国際化対応について解説を行ってきました。個々のアプリケーション・レベルで国際化に対応するとなると非常に大変な作業ですので、こうして言語レベルでの国際化サポートがあることは非常に重要なことです。
さて次回は、Mustang のその他の改善ということで、コア・ライブラリやネットワーク、セキュリティ関係の機能の解説を行います。
