こんにちは、落合です。
この記事は、TECHSCORE Advent Calendar の22日目の記事です。
2014年も終わろうとしていますね。
PostgreSQL8.x系は、今年EOLを迎えました。いままでありがとうございました。
(ですので9.x系で実施した記事内容となっています。)
そして、いまどきはMysqlというよりMariaDBにしたほうが刺さるんですかね?
そもそも、AWSでポチッとバックアップ&リカバリなんてしちゃうので、あんまり興味がなかったりでしょうか?(笑)
さて、、、記事タイトルのことをダラダラと・・・
オンラインバックアップのおさらい
まず、PostgreSQLとMysqlでみなさんが最初に実施したであろうバックアップ、
全データベースのオンラインバックアップをおさらいをしてみようとおもいます。
○PostgreSQL編
簡単ですね。
|
1 2 |
$ su - postgres $ pg_dumpall | gzip > postgresqldump-all.gz |
- | gzip >
- サイズが小さいことは何かとお得なので、gzipしておきます。
- ほかのオプションが無いが・・・?
- PostgreSQLの場合は、自動的に、読み取り一貫性機能が働きます。
- バックアップ取得中もデータベースへのアクセス(読み取り/書き込み)は抑制されません。
○Mysql編
ストレージエンジンにInnoDBを利用していることが前提
(MyISAM等は使えないオプションを含んでいます)
|
1 |
$ mysqldump -u root --all-databases --single-transaction --events | gzip > mysqldump-all.gz |
- --all-databases
- その名の通り、すべてのデータベースをdumpします。
- --single-transaction
- PostgreSQLと同じように読み取り一貫性機能が効くようになり、ロックもされません。とにかく付けておいて損はないです。
- dumpする前にBEGIN (transaction開始) SQLを使ってdumpするので、 ロックされることなくBEGIN 発行時点のdataをdumpできます。
- --events
- mysqlバージョン5.1.8からmysqlデータベースにeventsテーブルが追加されたことが原因で、
--all-databasesをつけると、
このテーブルだけが除外されるのでwarningがでます。これを抑止するためにつけています。
- mysqlバージョン5.1.8からmysqlデータベースにeventsテーブルが追加されたことが原因で、
- | gzip >
- サイズ縮小
ポイント・イン・タイム・リカバリ (PITR)
おさらいはいかがだったでしょうか?・・・さて、ここからが本題です。
○基本的なこと
- そもそもPITRって?
- 指定した時間に戻すことです。
- または、障害が起きる直前の状態まで戻すことです。
- Oracleでいうところの、完全/不完全リカバリ のことです。
- どうやって戻ってるの?
- 下記の絵の通り、
「 ベースバックアップ + 差分バックアップ 」
この二つのものを利用して戻します。
- 下記の絵の通り、
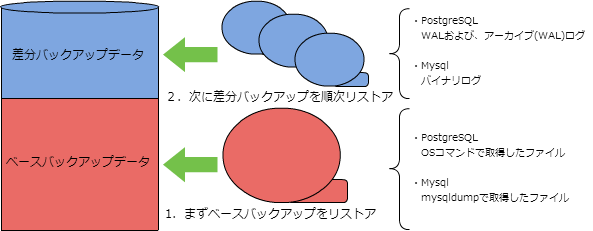
PITR:ベースバックアップの取得
○PostgreSQL編
- 開始宣言。これを実行すると以降の更新情報はディスクに反映されなくなります。
(メモリ上で頑張っています。)
これでデータベースの静止点が取れます。
|
1 |
$ psql -c "SELECT pg_start_backup(now()::text)" |
- OSコマンドでベースバックアップを取得します。
- postgresqlの起動プロセスファイル(postmaster.pid)やWALログ(pg_xlog)は不要です。
- ここでは、/postgresql_basebackup/配下に保存しています。
|
1 2 |
$ rsync -av --delete --exclude=pg_xlog --exclude=postmaster.pid \ /var/lib/pgsql/9.4/data/* /postgresql_basebackup/ |
- 終了宣言。 ベースバックアップ取得中に停止されていたデータベースの更新をディスクへ反映して通常の状態に戻ります。
|
1 |
$ psql -c "select pg_stop_backup()" |
※レプリケーション環境の場合は、専用ツール pg_basebackup がバージョン9.1から利用可能なのでそちらを使ってください。
○Mysql編
- ベースバックアップ取得方法
|
1 2 |
$ mysqldump -u root --all-databases --single-transaction --events \ --flush-logs --master-data=2 | gzip > mysqldump-all.gz |
- --flush-logs
- mysqldumpと同時に、bin-logをローテーションしてくれるので、リカバリがしやすくなります。
-
--master-data=2
-
msyqldumpで取得後、bin-logのどのファイルの何行目から復旧させればいいかdumpファイルにコメントとして書き込んでくれるすぐれたオプションです。
- ちなみに、レプリケーション構成を組んでなくても指定可能なので、PITRする人は積極的に利用すべきだと思います。
-
あれ、これだけ!? オンラインバックアップで使ったdumpと同じ?
そうです、オプションは少し増えた(例だと二つ)もののMysqlだとこれをベースバックアップとして利用可能なのです。
PITR:差分バックアップの取得
○PostgreSQL編
- アーカイブログを吐く設定(postgresql.confの編集)
|
1 2 |
archive_mode = on archive_command = 'cp %p /postgresql_archive_log/%f' # /postgresql_archive_log/配下に保存。 |
- %p:アーカイブするファイルのパス名に置換されます。
- %f:ファイル名部分のみに置換されます。
- WALを退避します。
- 最新のトランザクションログなので、完全リカバリを行いたい方は退避しておいてください。
- 最初から、別ディスクにpg_xlogを吐き出すようにしておくのも有効な手段です。
|
1 2 |
# /postgresql_wal_log/配下に保存。 $ rsync -av --delete /var/lib/pgsql/9.4/data/pg_xlog/* /postgresql_wal_log/ |
○Mysql編
- バイナリログを吐く設定(my.cnfの編集)
Mysqlではアーカイブログと呼ぶものではなく、バイナリログがその役割を担います。
|
1 2 3 4 5 |
[mysqld] #バイナリログ有効化: #datadir=/var/lib/mysql となっていれば(デフォルト)、 #/var/lib/mysql/配下にmybin-log.00000xというファイル名で保存される。 log-bin=mybin-log |
PITR:リカバリ
さていよいよリカバリです。
○PostgreSQL編
ゴミデータがあっては困るので、再インストールしたばかりのPostgreSQLがあって起動していない状態等を作っておいてください。
- 何はともあれ、まずは、ベースバックアップの戻し
|
1 |
$ rsync -av --delete /postgresql_basebackup/* /var/lib/pgsql/9.4/data/ |
- アーカイブ(WAL)ログを充てるための準備
- recovery.confにアーカイブ(WAL)ログが存在している場所を指定します。
|
1 2 |
restore_command = 'cp /postgresql_archive_log/%f "%p"' recovery_target_time = '2014-12-21 10:00:00' |
※ recovery_target_time の行を無くせば、WALが持っている最新の時刻まで戻ります。
- WALを充てるための準備
|
1 2 |
$ cd data $ rsync -av --delete /postgresql_wal_log/* /var/lib/pgsql/9.4/data/pg_xlog/ |
- PostgreSQLの起動
- これで差分バックアップのデータ(アーカイブログおよび、WAL)まで適用されていきます。
|
1 |
# /etc/init.d/postgresql-9.4 start |
○Mysql編
ゴミデータがあっては困るので、再インストールしたばかりのMysqlがあって起動した状態等を作っておいてください。
- 何はともあれ、まずは、ベースバックアップの戻し
|
1 |
gunzip --stdout mysqldump-all.gz | mysql -u root |
- ダンプ取得以降~復旧したい時間までに書き出されたバイナリログを確認
|
1 |
$ ls -ltr /var/lib/mysql/mybin-log.* |
- ダンプ開始時点のバイナリログ名と位置を確認
|
1 2 3 4 |
$ gunzip --stdout mysqldump-all.gz | head -30 | grep CHANGE ------------------------------ -- CHANGE MASTER TO MASTER_LOG_FILE='mybin-log.000011', MASTER_LOG_POS=107; ------------------------------ |
- 上記で確認したバイナリログ名と位置を指定して、ダンプ取得以降~復旧したい時間までのデータを書き出す
- ダンプ取得時に --flush-logs オプションを指定しているので開始位置は、先頭になっているので、
ずばり position で指定しています。
|
1 2 |
$ mysqlbinlog --start-position=107 --stop-datetime='2014-12-21 10:00:00' \ mybin-log.000011 > /tmp/recovery.sql |
- 例)ダンプ取得以降~復旧したい時間までに書き出されたバイナリログが複数の場合
|
1 2 3 4 5 |
$ mysqlbinlog --start-position=107 --stop-datetime='2014-12-21 10:00:00' \ mybin-log.000011 \ mybin-log.000012 \ mybin-log.000013 \ mybin-log.000014 > /tmp/recovery.sql |
※ --stop-datetime の指定がなければ、指定したバイナリログファイルが持っている最新の時刻までが対象になります。
- 差分バックアップデータの適用
|
1 |
$ mysql -u root < /tmp/recovery.sql |
まとめ の まとめ
いかがだったでしょうか? PostgreSQLとMysqlとでPITRの比較ができましたでしょうか?
そして今回の記事のまとめです。
| 手順 | PostgreSQL | Mysql |
|---|---|---|
| オンラインバックアップコマンド | pg_dumpall(または、pg_dump) | mysqldump |
| PITRのためのベースバックアップ取得方法 | 1.psql -c "SELECT pg_start_backup(now()::text)" 2.OSコマンドによる該当領域バックアップ 3.psql -c "select pg_stop_backup()" |
mysqldump |
| PITRで戻すために必要な差分バックアップファイルの種類 | 1.アーカイブ(WAL)ログ 2.WALログ ※Oracleでいう不完全リカバリの場合は不要な場合がある。 |
バイナリログのみ |
| PITRのための差分バックアップ取得方法 | 1.アーカイブログを吐く設定(postgresql.conf) 2.OSコマンドによるWALログの退避 |
バイナリログを吐く設定(my.cnf) |
| PITRで戻すためのアプリケーションの状態 | 停止 | 起動 |
| PITRで戻すためのベースバックアップ適用方法 | OSコマンドによる退避済みベースバックアップの戻し作業 | gunzip --stdout [mysqldumpで取得したファイル] | mysql -u root (または、mysql -u root < [mysqldumpで取得したファイル]) |
| PITRで戻すための差分バックアップ適用方法 | 1.退避済みアーカイブログの場所指定(recovery.conf) 2.退避済みWALログのOSコマンドによる戻し作業 3.PostgreSQLの起動 |
1.mysqlbinlogで、バイナリログをテキスト化 2.mysql -u root < 上記テキスト化したファイル |
ベースバックアップ+差分バックアップの仕組みを理解できれば、応用が利くようになります。
たとえば、Master/Slaveのレプリケーション構成で、HDD丸ごとクラッシュした場合、壊れたほうのDBはいずれ修復しないといけないですよね。
そんなとき、ベースバックアップを手動で戻してあげて、差分バックアップ部分については、レプリケーションで追いつかせる。
なんてことがスムーズに実行できるかとおもいます。
Oraclerな私でしたが、
Mysqlにはストレージエンジンだったり、この記事のようにオンラインバックアップがそのままベースバックアップとして使えたり驚きがありますね。
PostgreSQLはDDLにトランザクション張れる(ロールバックできる!)とか、SQLがTAB補完できたりとか驚かせられますね。
みなさんも、いろいろ比較してみてはいかがでしょうか?
