これは TECHSCORE Advent Calendar 2018 の18日目の記事です。
今回はPostgreSQLを運用する上で絶対に無視できない「VACUUM」について、その機能と役割を確認していきたいと思います。
VACUUMとは
VACUUMは、テーブルの実体となるファイルの中から、不要領域を探索し、再利用可能な状態にしていくものです。VACUUMを全く実行しない場合、ファイルサイズが増え続け、パフォーマンスの低下、ディスクスペースの圧迫へとつながります。
AUTO VACUUM機能
PostgreSQLには「AUTO VACUUM」機能が搭載されており、自動で随時VACUUMが実行されるため、多くの場合問題となりません。しかし、AUTO VACUUMも万能ではありません。テーブルによって追加・更新・削除の頻度、規模は様々であるため、AUTO VACUUM機能によるVACUUM実行のタイミングが適切でないケースがでてきます。
(AUTO VACUUMによるVACUUM実行のタイミングは設定により調整が可能です。autovacuum_vacuum_threshold、autovacuum_vacuum_scale_factor等)
なぜVACUUMが必要か
PostgreSQLは追記型アーキテクチャを採用しているためです。PostgreSQLが行の追加・更新・削除をどのように行うか、おおざっぱにですが確認していきましょう。
PostgreSQLはデータを8KB単位で管理します。空のテーブルに1行INSERTする場合、8KBの空き領域を準備し、そこにデータを格納します。
さらにINSERTを続け、8KBの空き領域が不足した場合、追加で8KBの領域を確保します。このタイミングでファイルサイズが大きくなることになります。
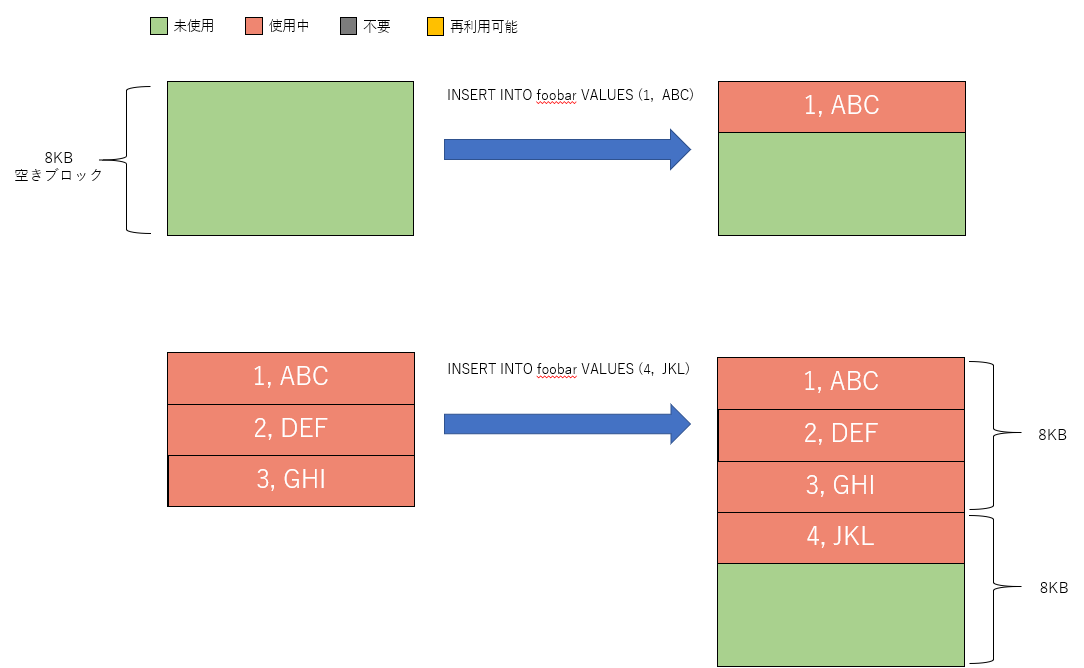
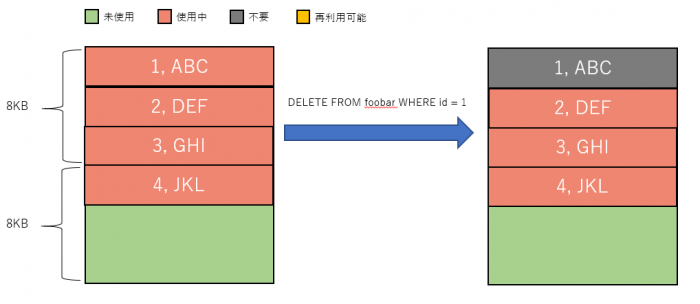
次にDELETEですが、DELETEは対象の行に「不要」という印付けを行うのみで、実際に消えることはありません。印付けられた行はそれ以降のトランザクションから見えなくなり、結果として削除されたこととなります。
次にUPDATEですが、DELETE + INSERTのような動作となります。UPDATE対象の行に「不要」という印付けを行い、更新内容を新しい行として追加します。
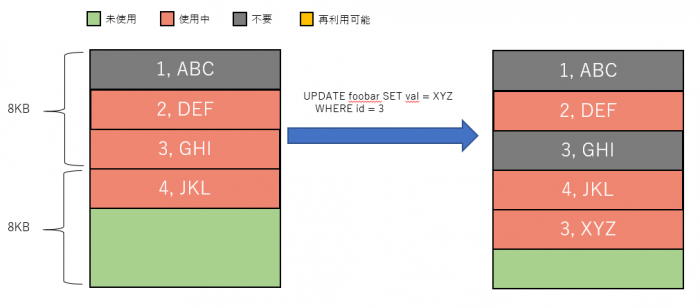
そのため、INSERT/UPDATE/DELETEを続けるとファイルサイズが大きくなり続けます。そこで、VACUUMです。
VACUUMでは「不要」と印付けされた領域を「再利用可能」として印付けます。再利用可能な領域は、以降のINSERT/UPDATE時に利用されます。

実際に試してみる(VACUUM)
テーブルに大量データを入れ、VACUUMの挙動を実際に確認してみましょう。
(ここでの検証にはPostgreSQLバージョン11.1を使用しました。)
テスト用のテーブルを準備します。
|
1 2 |
test=# CREATE TABLE foobar(id INTEGER, val TEXT); CREATE TABLE |
テーブルの実ファイルを確認します。
実ファイルはデフォルトで$PGDATA以下のbaseディレクトリ以下にデータベースごとにディレクトリが切られ、テーブルのrelfilenodeがファイル名となって配置されます。
データベースのIDと、テーブルのrelfilenodeを確認しましょう。
|
1 2 3 4 5 6 7 8 9 10 11 |
test=# SELECT datid, datname FROM pg_stat_database WHERE datname = 'test'; datid | datname -------+--------- 16384 | test (1 row) test=# SELECT relfilenode,relname FROM pg_class WHERE relname = 'foobar'; relfilenode | relname -------------+--------- 16418 | foobar (1 row) |
以上から、テーブルのファイルは $PGDATA/base/16384/16418 にあることがわかります。確認しましょう。
|
1 2 |
[postgres@testdb tmp]$ ls -lh $PGDATA/base/16384/16418* -rw------- 1 postgres postgres 0 12月 5 15:28 /tmp/testdb//base/16384/16418 |
ファイルサイズがゼロですね。
適当に1行INSERTしてみます。
|
1 2 |
test=# INSERT INTO foobar(id, val) VALUES (1, 'abc'); INSERT 0 1 |
|
1 2 |
[postgres@testdb tmp]$ ls -lh $PGDATA/base/16384/16418* -rw------- 1 postgres postgres 8.0K 12月 5 15:29 /tmp/testdb//base/16384/16418 |
ファイルサイズが8KBとなりました。
先ほど投入したidが1のものをSELECTしてみます。
|
1 2 3 4 5 6 7 8 |
test=# EXPLAIN ANALYZE SELECT * FROM foobar WHERE id = 1; QUERY PLAN -------------------------------------------------------------------------------------------------- Seq Scan on foobar (cost=0.00..25.62 rows=1 width=37) (actual time=0.016..0.019 rows=1 loops=1) Filter: (id = 1) Planning Time: 0.084 ms Execution Time: 0.043 ms (4 rows) |
1件しかデータがないので 1ms もかからないですね。
ではデータを一気に1000万件INSERTしてみます。
|
1 2 3 4 5 6 7 8 |
test=# INSERT INTO foobar(id, val) SELECT id,md5(clock_timestamp()::TEXT) AS val FROM generate_series(1,10000000) AS id; INSERT 0 10000000 test=# SELECT COUNT(*) FROM foobar; count ---------- 10000001 (1 row) |
最初にINSERTしたデータとあわせて10000001件です。
データの内容は以下のような感じです。
|
1 2 3 4 5 6 7 8 9 |
test=# SELECT * FROM foobar LIMIT 5; id | val ----+---------------------------------- 1 | abc 1 | d58fda95c19c28d37ea6e7f920775c26 2 | 7aee59e7193efcbc9621d8a3687aa522 3 | eb69b8be847b4384b2493f8e04b0106b 4 | 606173a18a62d2e8208f94e58e5751cd (5 rows) |
ファイルを確認すると一気に約650MBとなりました。
|
1 2 |
[postgres@testdb tmp]$ ls -lh $PGDATA/base/16384/16418* -rw------- 1 postgres postgres 652M 12月 5 15:34 /tmp/testdb//base/16384/16418 |
idが1のデータをSELECTしてみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
test=# EXPLAIN ANALYZE SELECT * FROM foobar WHERE id = 1; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------- Gather (cost=1000.00..138588.01 rows=1 width=37) (actual time=0.285..249.641 rows=2 loops=1) Workers Planned: 2 Workers Launched: 2 -> Parallel Seq Scan on foobar (cost=0.00..137587.91 rows=1 width=37) (actual time=161.653..243.944 rows=1 loops=3) Filter: (id = 1) Rows Removed by Filter: 3333333 Planning Time: 0.072 ms Execution Time: 249.674 ms (8 rows) |
さすがに約1000万件もデータがあるので遅いです。約250msかかるようになりました。
パラレルシーケンシャルスキャンが実装されていなかった時代だともっと気が遠くなるほど遅かったことでしょう。/(ツ)\
ここからが今回の本題です。
投入したデータをidが10000000のもの1件だけを残して削除してみます。
|
1 2 3 4 5 6 7 |
test=# DELETE FROM foobar WHERE id <= 9999999; DELETE 10000000 test=# SELECT COUNT(*) FROM foobar; count ------- 1 (1 row) |
データが1件だけになりました。ファイルサイズを確認してみます。
|
1 2 |
[postgres@testdb tmp]$ ls -lh $PGDATA/base/16384/16418* -rw------- 1 postgres postgres 652M 12月 5 15:42 /tmp/testdb//base/16384/16418 |
ファイルサイズが小さくなることはありません。かなしいですね。
idが1のデータをSELECTしてみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
test=# EXPLAIN ANALYZE SELECT * FROM foobar WHERE id = 1; QUERY PLAN --------------------------------------------------------------------------------------------------------------------------- Gather (cost=1000.00..144747.67 rows=52917 width=36) (actual time=101.558..102.279 rows=0 loops=1) Workers Planned: 2 Workers Launched: 2 -> Parallel Seq Scan on foobar (cost=0.00..138455.97 rows=22049 width=36) (actual time=98.330..98.331 rows=0 loops=3) Filter: (id = 1) Rows Removed by Filter: 0 Planning Time: 0.070 ms Execution Time: 102.305 ms (8 rows) |
先ほどよりもかなりマシではありますが、最初に1件だけINSERTしたときに比べるとかなり遅いですね。
ここまででDELETEをしてもファイルサイズが小さくなることはなく、パフォーマンスも低下することを確認できました。
もう一度1000万件のデータを投入します。
|
1 2 3 4 5 6 7 |
test=# INSERT INTO foobar(id, val) SELECT id,md5(clock_timestamp()::TEXT) AS val FROM generate_series(1,10000000) AS id; INSERT 0 10000000 test=# select count(*) from foobar; count ---------- 10000001 (1 row) |
ファイルサイズを確認してみます。
|
1 2 3 |
[postgres@testdb tmp]$ ls -lh $PGDATA/base/16384/16418* -rw------- 1 postgres postgres 1.0G 12月 5 15:46 /tmp/testdb//base/16384/16418 -rw------- 1 postgres postgres 279M 12月 5 15:47 /tmp/testdb//base/16384/16418.1 |
1279MBとなり、約2倍になっています。
(PostgreSQLはデフォルト設定で1GB毎にファイルを分割して管理します。)
VACUUMで不要領域を回収していなかったため、すべて新規に追記されてしまったようです。
SELECT性能をみてみましょう。先ほど約1000万件のデータがあるときは約 250ms でした。
今回は。。。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
test=# EXPLAIN ANALYZE SELECT * FROM foobar WHERE id = 1; QUERY PLAN ----------------------------------------------------------------------------------------------------------------------------- Gather (cost=1000.00..288493.68 rows=105834 width=36) (actual time=95.332..420.700 rows=1 loops=1) Workers Planned: 2 Workers Launched: 2 -> Parallel Seq Scan on foobar (cost=0.00..276910.28 rows=44098 width=36) (actual time=305.777..412.998 rows=0 loops=3) Filter: (id = 1) Rows Removed by Filter: 3333333 Planning Time: 0.071 ms Execution Time: 420.737 ms (8 rows) |
約420msとなり、さらにパフォーマンスが低下してしまいました。
再度、idが10000000以外のものを削除します。
|
1 2 3 4 5 6 7 |
test=# DELETE FROM foobar WHERE id <= 9999999; DELETE 9999999 test=# select count(*) from foobar; count ------- 2 (1 row) |
残っているデータは2件だけです。SELECT性能はどうでしょうか。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
test=# EXPLAIN ANALYZE SELECT * FROM foobar WHERE id = 1; QUERY PLAN ----------------------------------------------------------------------------------------------------------------------------- Gather (cost=1000.00..288493.68 rows=105834 width=36) (actual time=191.770..194.099 rows=0 loops=1) Workers Planned: 2 Workers Launched: 2 -> Parallel Seq Scan on foobar (cost=0.00..276910.28 rows=44098 width=36) (actual time=188.356..188.357 rows=0 loops=3) Filter: (id = 1) Rows Removed by Filter: 1 Planning Time: 0.071 ms Execution Time: 194.127 ms (8 rows) |
データが2件しかないにもかかわらず約200msもかかってしまっています。これはひどい。
VACUUMの効果を試してみましょう。
これまでにDELETEした約2000万件の不要データの領域を再利用可能にします。
|
1 2 |
test=# VACUUM foobar; VACUUM |
ファイルサイズを確認します。
|
1 2 3 |
[postgres@testdb tmp]$ ls -lh $PGDATA/base/16384/16418* -rw------- 1 postgres postgres 1.0G 12月 5 16:09 /tmp/testdb//base/16384/16418 -rw------- 1 postgres postgres 279M 12月 5 16:10 /tmp/testdb//base/16384/16418.1 |
再利用可能にするだけなので、変化はありません。
もう一度1000万件のデータを投入します。
|
1 2 |
test=# INSERT INTO foobar(id, val) SELECT id,md5(clock_timestamp()::TEXT) AS val FROM generate_series(1,10000000) AS id; INSERT 0 10000000 |
ファイルサイズを確認します。
|
1 2 3 |
[postgres@testdb tmp]$ ls -lh $PGDATA/base/16384/16418* -rw------- 1 postgres postgres 1.0G 12月 5 16:13 /tmp/testdb//base/16384/16418 -rw------- 1 postgres postgres 279M 12月 5 16:13 /tmp/testdb//base/16384/16418.1 |
再利用可能な領域に1000万件のデータが格納されたので変化はありません。
まだ再利用可能な領域が残っているはずなので、さらに1000万件行きましょう。
|
1 2 |
test=# INSERT INTO foobar(id, val) SELECT id,md5(clock_timestamp()::TEXT) AS val FROM generate_series(1,10000000) AS id; INSERT 0 10000000 |
ファイルサイズを確認します。
|
1 2 3 |
[postgres@testdb tmp]$ ls -lh $PGDATA/base/16384/16418* -rw------- 1 postgres postgres 1.0G 12月 13 13:00 /tmp/testdb/base/16384/16418 -rw------- 1 postgres postgres 279M 12月 13 13:01 /tmp/testdb/base/16384/16418.1 |
サイズは変わっていません。再利用可能な領域に収まりきったようです。
VACUUMの効果が出ていますね。
定期的にVACUUMを実行していればファイルサイズの肥大化を抑制できることを確認できました。
しかし、VACUUMでは一度肥大化してしまったテーブルを小さくすることはできませんし、低下してしまったパフォーマンスも改善しません。あくまでも抑制にしかならないのです。
ここで VACUUM FULL の出番です。
実際に試してみる(VACUUM FULL)
もう一度idが10000000のものを残して削除します。
|
1 2 3 4 5 6 7 |
test=# DELETE FROM foobar WHERE id <= 9999999; DELETE 19999998 test=# SELECT COUNT(*) FROM foobar; count ------- 4 (1 row) |
残ったデータは4件のみです。
VACUUMをしてみますが、当然、ファイルサイズは変わりません。
|
1 2 3 4 5 6 |
test=# vacuum foobar ; VACUUM [postgres@testdb tmp]$ ls -lh $PGDATA/base/16384/16418* -rw------- 1 postgres postgres 1.0G 12月 13 13:10 /tmp/testdb/base/16384/16418 -rw------- 1 postgres postgres 279M 12月 13 13:10 /tmp/testdb/base/16384/16418.1 |
パフォーマンスも悪いままです。
|
1 2 3 4 5 6 7 8 9 |
test=# EXPLAIN ANALYZE SELECT * FROM foobar WHERE id = 1; QUERY PLAN ---------------------------------------------------------------------------------------------------------- Seq Scan on foobar (cost=0.00..166667.10 rows=1 width=36) (actual time=349.559..349.559 rows=0 loops=1) Filter: (id = 1) Rows Removed by Filter: 8 Planning Time: 0.067 ms Execution Time: 349.585 ms (5 rows) |
データ4件のみで約350ms。。。
それではいよいよVACUUM FULLを実行します。
|
1 2 |
test=# VACUUM FULL foobar; VACUUM |
VACUUM FULLでは新しいファイルにデータを整理して入れなおされるので、再度ファイル名を確認します。
|
1 2 3 4 5 |
test=# SELECT relfilenode,relname FROM pg_class WHERE relname = 'foobar'; relfilenode | relname -------------+--------- 16424 | foobar (1 row) |
ファイルを確認します。
|
1 2 |
[postgres@testdb tmp]$ ls -lh $PGDATA/base/16384/16424* -rw------- 1 postgres postgres 8.0K 12月 13 13:14 /tmp/testdb/base/16384/16424 |
データが4件しかないので1ブロックに収まり、ファイルサイズが8KBとなりました!
|
1 2 3 4 5 6 7 8 9 |
test=# EXPLAIN ANALYZE SELECT * FROM foobar WHERE id = 1; QUERY PLAN ------------------------------------------------------------------------------------------------- Seq Scan on foobar (cost=0.00..1.05 rows=1 width=37) (actual time=0.067..0.069 rows=0 loops=1) Filter: (id = 1) Rows Removed by Filter: 4 Planning Time: 0.130 ms Execution Time: 0.094 ms (5 rows) |
SELECT性能も完全に復活です!
VACUUMの例外ケース
VACUUMではファイルサイズが小さくならないことを確認しましたが、VACUUMでも小さくなる場合があります。それは、ファイル末尾から連続して不要領域が存在する場合です。このとき、PostgreSQLはファイルを切り詰めます。
これまでの動作確認で DELETE FROM foobar WHERE id <= 9999999; としていたのはそのためです。WHERE句を id > 1; とするとファイルが切り詰められ、小さくなります。確認してみましょう。
|
1 2 3 4 5 |
test=# INSERT INTO foobar(id, val) SELECT id,md5(clock_timestamp()::TEXT) as val FROM generate_series(1,10000000) AS id; INSERT 0 10000000 [postgres@testdb tmp]$ ls -lh $PGDATA/base/16384/16424* -rw------- 1 postgres postgres 652M 12月 13 15:45 /tmp/testdb/base/16384/16424 |
上の状態から、idが1のデータ(ファイルの先頭領域に格納されていると想定される)のみを残して削除します。
|
1 2 3 4 5 6 7 |
test=# DELETE FROM foobar WHERE id > 1; DELETE 9999999 test=# SELECT COUNT(*) FROM foobar; count ------- 1 (1 row) |
VACUUMを実行し、ファイルサイズを確認します。
|
1 2 3 4 5 |
test=# VACUUM foobar; VACUUM [postgres@testdb tmp]$ ls -lh $PGDATA/base/16384/16424* -rw------- 1 postgres postgres 8.0K 12月 13 15:47 /tmp/testdb/base/16384/16424 |
先頭領域のみを残してすべて消えてしまいましたね。
※この挙動は公式ドキュメントに記載がないため、変更される可能性があります。
最後に
VACUUM FULLはテーブルに排他ロックを必要とするうえ、処理に非常に長い時間を要します。そのため、VACUUM FULLの実行がサービス障害につながることもありえます。
VACUUM FULLが必要とならないよう、普段から適切にVACUUMが実行されるようにAUTO VACUUMのパラメータ調整や、各テーブルのVACUUM実行状況の監視が大切です。
年末に大掃除しなくていいように普段からこまめに掃除することが大切ですねo(ツ)9
