どうも。村上です。
今回で3回目のPostgreSQLです。
今はこんな感じです。
追記型アーキテクチャ
バキューム
Visibility Map ← 前回ここまで
プラン演算子 ← 今回ここ
Index Only Scan
では「プラン演算子」いってみよう!!
プラン演算子???
プラン演算子ってあまり聞きなれないですけど、簡単に言うと「explain」したら出てくるアレです。
|
1 2 3 4 5 |
=# explain select * from users; QUERY PLAN ------------------------------------------------------------------- Seq Scan on users (cost=0.00..385179.80 rows=10010480 width=190) |
上の「Seq Scan」ってのがプラン演算子です。
データを探しに行くときに、いろいろな探し方があります。
上から順に探したり、データがありそうな場所を探したりなどです。
その「探し方」が「プラン演算子」というイメージです。
ではプラン演算子をいろいろと見ていきましょう。
Seq Scan
まずは「Seq Scan」から!!
Seq Scanは最も基本的なもので、単に表を最初から最後へとスキャンするプラン演算子です。
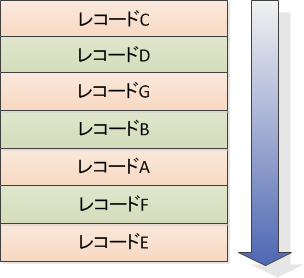
Explainではこんな感じです。
|
1 2 3 4 5 |
QUERY PLAN ----------------------------------------------------------------------- Seq Scan on users (cost=0.00..410075.00 rows=1 width=190) |
全行スキャンするので、レコードの多いテーブルには不向きです。
そういう時は次に説明するIndex Scanが良いです。
Index Scan
まずはexplainの結果から
|
1 2 3 4 5 |
=# explain select * from users where login = 'example_id'; QUERY PLAN -------------------------------------------------------------------------------- Index Scan using users_login_idx on users (cost=0.00..27.96 rows=1 width=190) Index Cond: ((login)::text = 'example_id'::text) |
コストの部分を見るとSeq Scanとくらべて随分少ない値になっています。
なんか速そうですね。
- IndexはIndex情報をツリー上に格納しています。
- 検索条件に合うインデックスがあれば、インデックスを探索します。
- 対象のデータが見つかれば、該当の行にアクセスしてデータを返します。
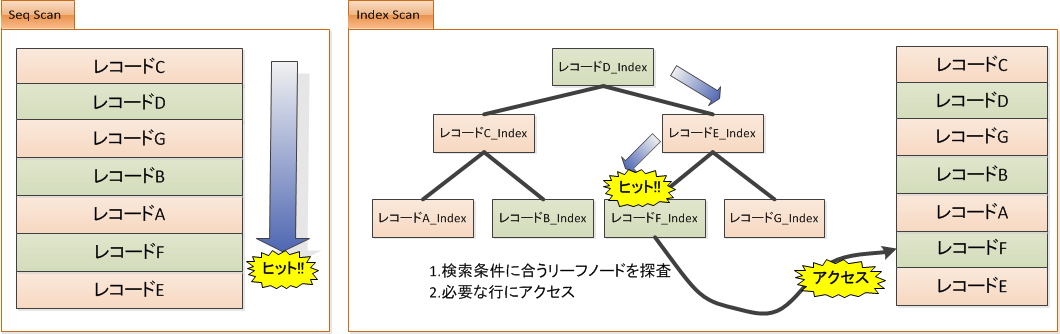
データ量が多い時はIndex Scanはかなり有効なのですが、少ない時はSeq Scanの方が速かったりします。
PostgreSQLのオプティマイザがそこら辺を考えて状況に応じてIndex Scanを使うかSeq Scanを使うかを判断します。
あと、Index Scanはデータ量が多い時に有効なのですが、それは参照の時です。
Insertでデータが挿入される場合は遅くなります。
IndexがあるテーブルにはIndex情報も更新する必要があるため、Insert処理が遅くなってしまいます。
とは言っても、1件のInsertぐらいではあまり変わりませんが、100万件Insertしようとするとかなりコストが変わります。
対象データの取込は以前に書いたのでそちらを見て下さい。
大量データ取込のいろいろ-postgresql編
Nested Loop
続いて結合系です。
まずはNested Loopからです。
- Nested Loopは単純な結合方式です。
- 外側のテーブル一行ごとに内側のテーブルを走査します。
- 外側のテーブルの件数が少なく、かつ、内側テーブルに結合キーのインデックスがある場合に有効です。
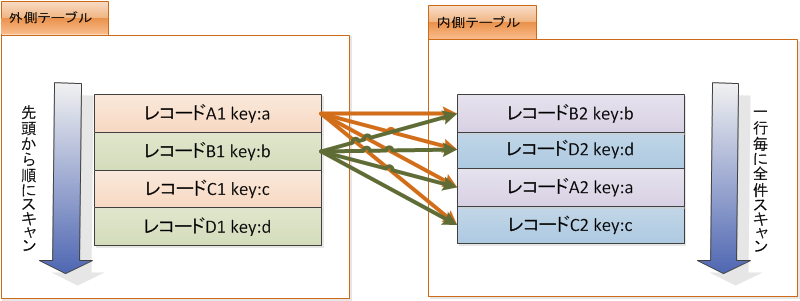
図はインデックスがない場合の図です。
内側テーブルをSeq Scanするので遅いです。
テーブルのサイズが大きくなればコストは膨らみます ⇒ 計算量はO(N×M)
結合キーでIndexがある場合は、内側テーブルの検索時はIndex Scanとなり高速化ができます。
EXPLAINはこんな感じです。
|
1 2 3 4 5 6 7 8 |
=# explain select * from regt_users as u join addresses as a on u.address_id = a.address_id; QUERY PLAN --------------------------------------------------------------------------------------------------------------------- Nested Loop (cost=0.00..30878348.84 rows=129415 width=138) Join Filter: (u.address_id = a.address_id) -> Seq Scan on regt_users u (cost=0.00..252.00 rows=10000 width=88) -> Materialize (cost=0.00..5576.40 rows=124627 width=50) -> Seq Scan on addresses a (cost=0.00..3735.27 rows=124627 width=50) |
Merge Join
次はMerge Joinです。
- Merge Joinは結合キーでソートし、マッチングしていきます。
- 外側のテーブルは1回調べれば良く、走査回数が減ります。
- 処理対象の行が多いケースに有効です。
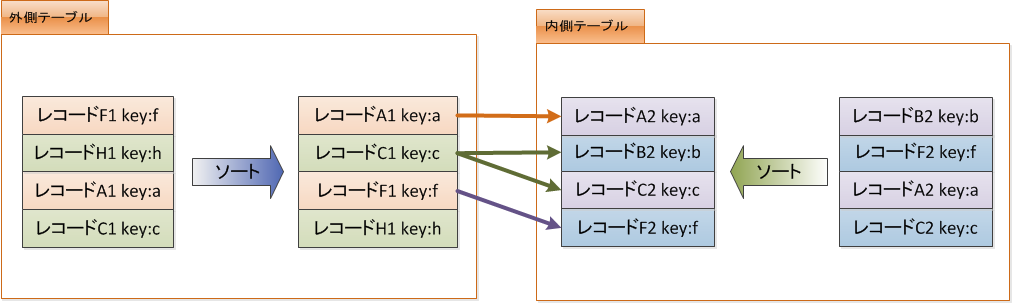
ソートさえ出来れば速いけど、ソートが遅いと余り有効ではないです。
Merge Joinも結合キーでインデックスを作成すれば、速くなります。
結論として、インデックス重要ということですね。
EXPLAINはこんな感じです。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
=# explain select * from regt_users as u join addresses as a on u.address_id = a.address_id; QUERY PLAN --------------------------------------------------------------------------------------------------------------------- Merge Join (cost=19517.82..20300.26 rows=10000 width=138) Merge Cond: (a.address_id = u.address_id) -> Sort (cost=18121.88..18425.68 rows=121523 width=50) Sort Key: a.address_id -> Seq Scan on addresses a (cost=0.00..3704.23 rows=121523 width=50) -> Materialize (cost=1395.89..1445.89 rows=10000 width=88) -> Sort (cost=1395.89..1420.89 rows=10000 width=88) Sort Key: u.address_id -> Seq Scan on regt_users u (cost=0.00..252.00 rows=10000 width=88) |
Hash Join
続いてHash Joinです。
- Merge Joinは内側のテーブルのハッシュ表を作成します。
- 外側のテーブルはハッシュ表と付きあわせて結合していきます。
- ハッシュ表はメモリに作るので、一度作ってしまえば高速で動作します。
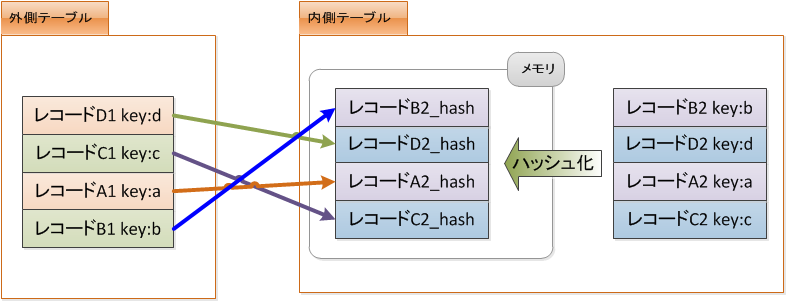
ハッシュはメモリに作られるので速いのですが、ハッシュ表のサイズがメモリサイズより大きくなればかなり遅くなってしまいます。
EXPLAINはこんな感じです。
|
1 2 3 4 5 6 7 8 |
=# explain select * from regt_users as u join addresses as a on u.address_id = a.address_id; QUERY PLAN -------------------------------------------------------------------------------- Hash Join (cost=6410.27..8298.27 rows=10000 width=138) Hash Cond: (u.address_id = a.address_id) -> Seq Scan on regt_users u (cost=0.00..252.00 rows=10000 width=88) -> Hash (cost=3704.23..3704.23 rows=121523 width=50) -> Seq Scan on addresses a (cost=0.00..3704.23 rows=121523 width=50) |
プラン演算子の無効化
上記にある結合系のEXPLAINですが、すべて同じSQLです。
でも、異なる実行計画を使ってます。
なぜか!?
実はプラン演算子を無効にする魔法があります。
そうしないと、全部Hash Joinになってしまうので。。。
|
1 2 3 4 5 |
set ENABLE_MERGEJOIN to off; -- Merge Join を無効に set ENABLE_HASHJOIN to off; -- Hash Join を無効に set ENABLE_MERGEJOIN to on; -- Merge Join を有効に set ENABLE_HASHJOIN to on; -- Hash Join を有効に |
こうすれば、プラン演算子を制御できます。
システムの運用中にすることは推奨できませんが、この実行計画でいいの!?
って時に調べるにはいいですね。
まとめ
今回はプラン演算子についてでした。
もうお気づきとは思いますが、「Index Only Scan」はプラン演算子の1つです。
ということで次回はIndex Only Scanについてです。
追記型アーキテクチャ
バキューム
Visibility Map
プラン演算子 ← イマココ
Index Only Scan ← ツギココ
