こんにちは、岡崎です。
この記事は TECHSCORE Advent Calendar 2017 の 19 日目の記事です。
今回紹介するのは「異なる言語から作られた2つの単語ベクトル空間をつなげる変換行列を学習する」という話です。
これは元々、機械翻訳で必要な「単語・フレーズ辞書」を自動的に生成するために Google の Tomas Mikolov によって提案されました。*1
単語ベクトルをつなげる変換行列とは
機械翻訳とは端的に言うと、片方の言語の言葉を他方の言語の言葉に変換することです。
変換には2つの言語間の単語やフレーズをマッピングした辞書 (日本語「猫」:英語「cat」などの意味対応辞書) を用いますが、網羅性がある良い辞書を作るのはとても手間がかかります。*2
そこで Mikolov は自動的にこの辞書を生成することができないかと考えました。
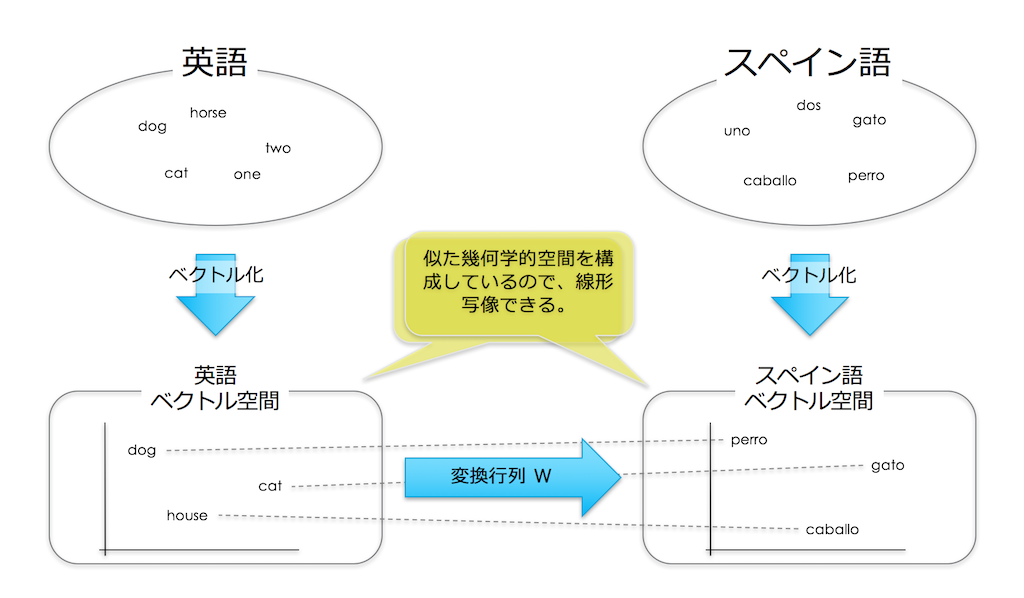
Mikolov は様々な言語の単語ベクトル空間を可視化しているときに「異なる言語でも似たような単語の位置関係がつくられる(相対的な位置関係が似ている)こと」に気付きました。
そして、それぞれの空間はシンプルに線形写像できて(空間で言うところの回転やスケーリング)、半自動的に辞書を作ることができるのではないかと考え、その可能性をこの論文で示しました。
ここでは Mikolov は一つの大きな仮定を置いています。
それは、「異なる言語においても、それぞれのベクトル空間が似た幾何学的空間を構成している」ということです。
そしてそれ故にシンプルに線形写像できる、と結論づけています。
アルゴリズム
考え方とアルゴリズムはとてもシンプルです。
- それぞれの言語で単語ベクトル(CBOW/skip-gram など)を準備します。
- 次に、それぞれの言語をつなぐ上で「種」となる単語対応辞書を準備します(例: {dog:perro, cat:gato, .....} 論文では約 5,000 語)。
- それぞれの言語の種の単語ベクトルから変換行列を学習します。
論文によると、変換行列は次の損失関数を最小化するように確率的勾配降下法で学習します。


ここで W は学習する変換行列、x は写像元、z は写像先、n は種の単語数です。
こうやって学習された変換行列は、それぞれのベクトル空間をシンプルに線形写像するものとなります。
コード
今回は tensorflow を用いました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 |
#!/usr/bin/env python # -*- coding: utf-8 -*- import sys import os import math import numpy as np os.environ['TF_CPP_MIN_LOG_LEVEL']='2' import tensorflow as tf import gensim, logging logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO) """ python 2.7.14 gensim (3.2.0) tensorflow (1.4.1) numpy (1.13.3) """ # 1. まず、それぞれの言語で単語ベクトル(CBOW/skip-gram など)を準備します # (ここでは word2vec バイナリフォーマットのモデルを想定しています。) model_file_a = "language_A.bin" model_file_b = "lbngubge_B.bin" model_a = gensim.models.KeyedVectors.load_word2vec_format(model_file_a, binary=True) model_b = gensim.models.KeyedVectors.load_word2vec_format(model_file_b, binary=True) # 2. 次に、それぞれの言語をつなぐ上で「種」となる単語対応辞書を準備します # 予め準備されているとします( vocab_dic = {'dog':'perro', 'horse':'caballo' .... )。 # 2'. それぞれの言語の種の単語ベクトルを抽出します. vocab_a, vocab_b = vocab_dic.keys(), vocab_dic.values() vec_a = model_a[vocab_a] vec_b = model_b[vocab_b] # 3. それぞれの言語の種の単語ベクトルから線形写像行列を学習します。 # ベクトル空間次元数 _, dvec_x = vec_a.shape _, dvec_z = vec_b.shape # 写像元 x = tf.placeholder(tf.float32, [None, dvec_x]) # 写像先 z = tf.placeholder(tf.float32, [None, dvec_z]) # 変換行列:標準偏差 0.01 のガウス分布で初期化 W = tf.Variable(tf.random_normal([dvec_x, dvec_z], stddev=0.01)) # 損失関数定義 $L = \sum_{i=1}^n || Wx_i - z_i ||^2$ loss = tf.reduce_sum(tf.square(z - tf.matmul(x, tf.transpose(W)))) # Adam オプティマイザを確率的勾配降下法に使います. train_step = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss) def next_batch(num, data, labels): ''' バッチ処理関数 https://stackoverflow.com/questions/40994583/how-to-implement-tensorflows-next-batch-for-own-data/40995666 Return a total of `num` random samples and labels. ''' idx = np.arange(0 , len(data)) np.random.shuffle(idx) idx = idx[:num] data_shuffle = [data[ i] for i in idx] labels_shuffle = [labels[ i] for i in idx] return np.asarray(data_shuffle), np.asarray(labels_shuffle) # 学習 with tf.Session() as sess: sess.run(tf.global_variables_initializer()) # バッチサイズ 100 の確率的勾配降下法を10000回行う for i in range(10000): batch_x, batch_z = next_batch(100, vec_a, vec_b) sess.run(train_step, feed_dict={x: batch_x, z:batch_z}) if i % 1000 == 0: print 'Step: %d, Loss: %f'% (i, sess.run(loss, feed_dict={x: batch_x, z:batch_z})) # 学習した変換行列を抽出 W_ = sess.run([W]) print W_[0] |
まとめ
今回は「異なる言語から作られた2つの単語ベクトル空間をつなげる変換行列を学習する」という話をしました。
アルゴリズムとしてはとてもシンプルで、前述の強い仮定「異なるドメインのデータにおいて、それぞれのベクトル空間が似た幾何学的空間を構成している」がそれを可能にしています。
この論文の肝はこの仮定ですが、それが成り立ちそうなデータであればシンプルなだけに様々なことに応用できそうです。
例えば、似たような商材を扱っている EC で、双方で似たような売れ方をしている商品がわかるようになるかもしれません。
翻訳の文脈で提案された技術ですが、マーケティングにも活用できるとしたらおもしろいですね。
今、機械学習では「転移学習」や「ドメイン適応」が注目されています。
「転移学習」や「ドメイン適応」においても、異なるドメインのデータの分布の違いに対する仮定をどのように置くのか、というのは大切なポイントとなります。
この Mikolov の論文は少し昔のものなのですが、そういった観点でみると以前読んだときとはまた異なる捉え方ができて新鮮でした。
機械学習をしていると、少ないデータや偏ったデータなどを使わざるを得ない場合も多々あると思います。
既に定評のあるモデルや直接的に関係のないデータをドメイン適応して活用することも今後は増えるでしょうし、そういったところにも新たなビジネスシードが出てくるかもしれません。
参照
- Exploiting Similarities among Languages for Machine Translation
- 現在の機械翻訳ではこういった単語・フレーズ辞書はそれほど重用しない、ニューラルネットワークのモデル(エンコーダ・デコーダやその改良であるアテンション)が主流です。
- 実はこの変換行列を学習する機能は既に gensim に実装されています(執筆中に気づきました ^^;)。
