これは 😺TECHSCORE Advent Calendar 2018😺の21日目の記事です。
今回まじめにデータ分析を行うプロジェクトに携わることになり、その取り掛かりに確認したことを少し記事にします。
データ分析においてPythonは今やデファクトスタンダードな存在です。 普段はインフラ寄りの仕事が多い著者ですが、元々はプログラミングのほうが好きなので(遊ぶために)何かとPythonを使います。 ちょっとしたログ集計もPandasモジュールなんかを使えば
|
1 2 3 4 5 6 |
KEY,VALUE a,10 b,12 c,3 b,3 c,5 |
|
1 2 3 4 5 6 |
python -c "import pandas; csv = pandas.read_csv('hoge.csv'); print(csv.groupby(csv.KEY).sum())" VALUE KEY a 10 b 15 c 8 |
という具合にLinuxコマンドのsort & uniqフィルタのようにワンライナーで書けてしまいます。
ここから本題ですが、データ分析というのは"データを分類し、それらに何某かの処理を行い、その結果を結合する"という操作のイテレーションです。
簡単な集計・ワンパスの処理ならば上記のように軽微に済ませれば良いですが、少し大きなデータを扱う際はこの操作のスピードが重要になってきます(イテレーションが10の何乗もにもなる場合を考えてみればその意味がわかりますよね)。
ちゃんとした分散データ処理基盤があれば良いのですが、ちょっとした調査・検証のためだけに用意するわけにもいかないです。
そこで効率的なデータ分析を行うためにPythonにおけるいくつかの分類(Group-By)+集計の方法を確認してみました。
なお今回の検証環境は以下の通りです。
- Python version: 3.6.6 (セットアップは割愛します)
- Processor: 第7世代インテルCore i5 2.3 GHz
- Memory: 16 GB
1. 愚直に足し上げる
まず愚直にループ実行をしてディクショナリデータに足し上げてみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
from collections import defaultdict import random import timeit def pseudo_data(n, size, seed=12345678): random.seed = seed keys = ["KEY-{}".format(i) for i in random.choices(range(0, n), k=size)] values = random.choices([0, 1], k=size) return keys, values def group_by(keys, vals): d = defaultdict(int) for key, val in zip(keys, vals): d[key] += val return d global keys, values keys, values = pseudo_data(n=10**2, size=10**5) result = timeit.timeit("group_by(keys, values)", globals=globals(), number=100) print("Average time: {:.2e} sec.".format(result/100)) |
ここでは検証用に105の偽データを用意してそれを集計します。各データは100種類の項目のうちのいずれか1つで、各々は0か1の値を持ちます。pseudo_dataは偽データを生成する関数、group_byがグルーピング+集計をする関数です。集計時間の計測にはtimeitモジュールを使い、100回実行したときの平均実行時間を求めています。
|
1 |
Average time: 1.11e-02 sec. |
2. itertoolsを使う
Pythonではループ実行のためのイテレータ生成のためにはitertoolsを使いますが、このモジュールにもgroupbyイテレータが用意されています。
このイテレータを使って上記のgroup_by関数をざっくり書き換えると
|
1 2 3 4 5 6 |
from itertools import groupby def group_by(keys, vals): data = zip(keys, vals) sorted_pairs = sorted(data, key=lambda x: x[0]) return {key: sum(map(lambda x: x[1], val)) for key, val in groupby(sorted_pairs, lambda x: x[0])} |
という具合でしょうか。集計の速度は
|
1 |
Average time: 9.54e-02 sec. |
かなり遅いですね。itertools.groupbyを意図通りに使用するためにはオブジェクトはソート済みでないといけないため、このイテレーションで余計な時間がかかっていそうです。
3. Pandasを使う
冒頭にもう出してしまいましたが、データ分析用ライブラリPandasを用いると記述も簡単。
|
1 2 3 4 |
import pandas def group_by(keys, vals): return pandas.Series(vals).groupby(keys).sum().to_dict() |
実行結果は
|
1 |
Average time: 1.16e-02 sec. |
とそこそこ速い。実はこれまでPandasを使用していても速いと感じたことがなかったので少し意外です。
4. 更なる高みへ
もっと高効率な実装がないかと調べてみたところ、スパース行列を用いる方法があるとのこと。またPandasドキュメントによるとMulti-index DataFrameから簡単にSciPyモジュールのスパース行列を作成することができそう。
これを用いてgroup_by関数を書き直したものが以下の通りです。
|
1 2 3 4 5 6 7 8 9 |
import numpy import pandas def group_by(keys, vals): unique_keys, rows = numpy.unique(keys, return_inverse=True) columns = numpy.arange(len(keys)) df = pandas.DataFrame(vals, index=[rows, columns]) matrix = df.to_sparse().to_coo() return dict(zip(unique_keys, matrix.sum(axis=1).flat)) |
ここでは行・列・値のタプルのリストとして表現(COO: coordinate format)されるスパース行列を使います。なお行列要素のランダムアクセスを効率化するためにソート済みのインデックスを指定してDataFrameを作成し、集計にはscipy.sparse.coo_matrixに用意されているsum関数を用いて合算しています。
しかし実行結果はそれほど速くない。
|
1 |
Average time: 3.46e-02 sec. |
もう少し傾向を見てみるためにグループ数(G)、データサイズ(N)に対する計算時間を図に纏めてみました。
- 左: G=100で固定、Nを変更した場合
- 中: N=105で固定、データサンプル内のGを変更した場合
- 右: N=107で固定、データサンプル内のGを変更した場合
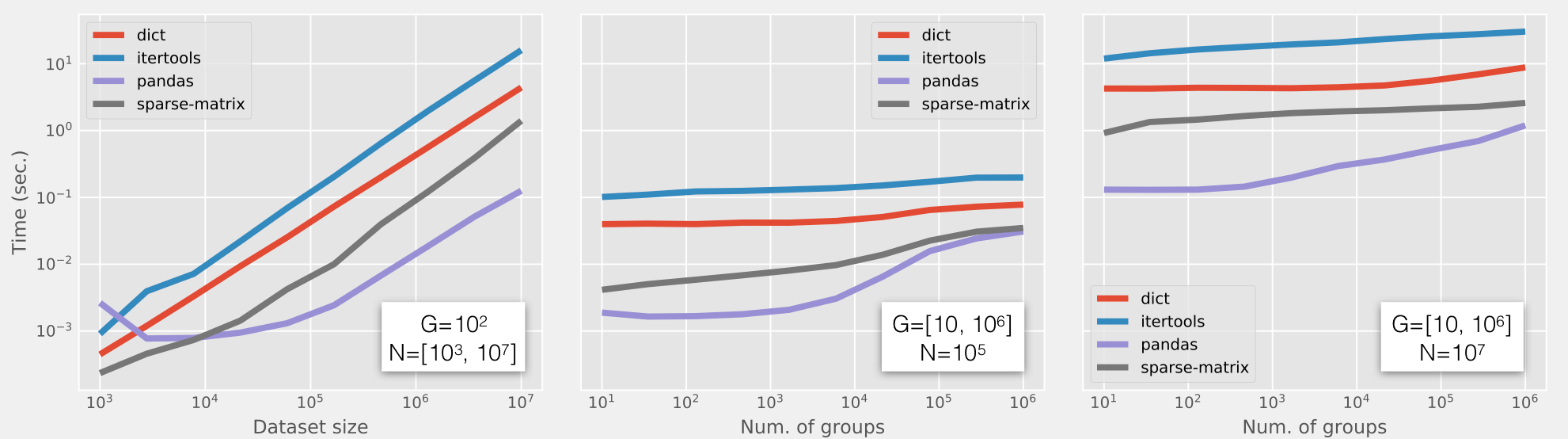
データサイズが増えると計算時間も比例して増えるのは自明ですね。Pandasフレームワークで小統計データを扱うときにパフォーマンスが劣化してるのはきちんと実装を追っていないので理解できていません。以前から遅いと感じていたのはこのあたりの領域で使用していたからでしょうか… この傾向はグループ数を増減してもあまり変わりません。グループ数が増えてくるとスパース行列による計算は速度も安定し、良い結果を示しています。
(フェアな比較のためにキャッシュに載せて実行し、また各点の比較は同一のデータサンプルを使っています。)
さいごに
無数のイテレーションを行うデータ分析においてグルーピング処理の速度は非常に重要です。何も意識しないで実装してしまうと何10倍も処理が遅くなってしまう可能性があります。扱うデータのサイズや分類の粒度を考えてデータ分析に着手する段階からちゃんと気をつけたいですね。
