これは TECHSCORE Advent Calendar 2017の7日目の記事です。
背景
こんにちは。土屋です。
皆さんはサーバー監視のツールとして人気が上がってきている、 Prometheus をご存知でしょうか。
どのくらい人気か、Google トレンドで他の監視ツールと合わせて調べてみました(※)。
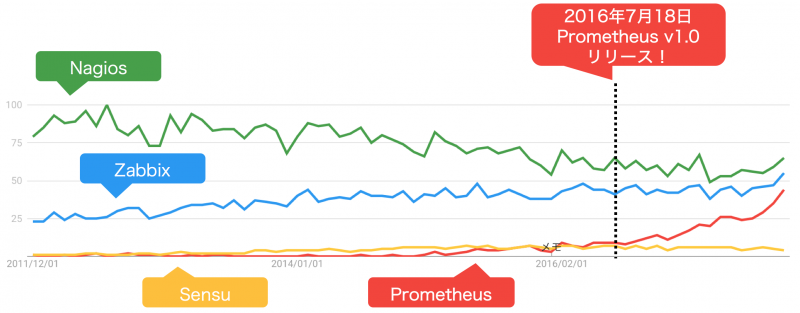
※"[監視ツール] monitoring" で検索しています
図から見てもわかる通り、Prometheus のバージョン 1.0 が出てから現在まで右肩上がりになっています。
これは使ってみなければ!ということで、Prometheus を使ってサーバー監視を設定してみました。
しかし私はほんの1ヶ月前まで全くサーバー監視をしたことがなく、設定周りで慣れぬこともあり、環境構築に思いのほか時間がかかってしまいました。
基本的な監視方法で、かつ Prometheus や Alertmanager などの各種設定が1つにまとまっているサイトがあればいいな、と思い今回の記事を書くに至りました。
ゴール
Prometheus で監視ができるよう、インストールから起動、グラフを見るところまで行います。
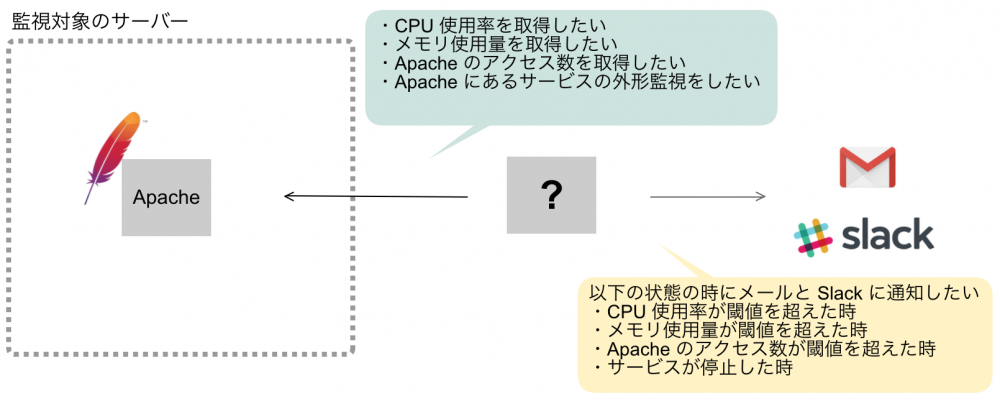
上図のような要望があったとして、これらの要望を満たすため、今回は次のような環境構築をします。
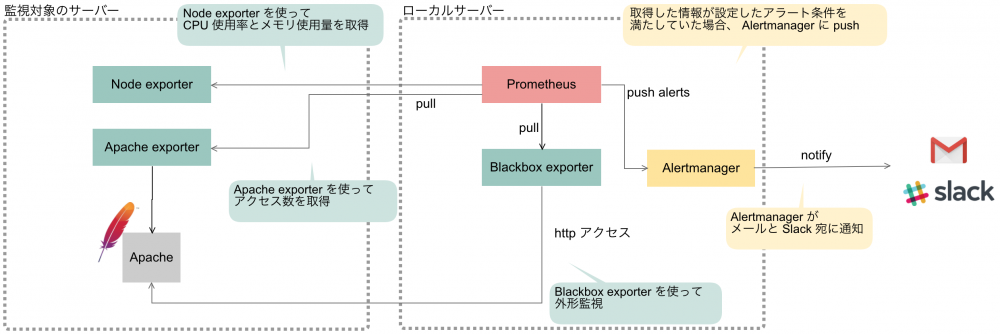
なお、環境は次の通りです。Prometheus, Node exporter, Alertmanager Apache exporter, Blackbox exporter のバージョンは執筆時点で最新のものです。
- OS: macOS Sierra
- Prometheus: v2.0.0
- Node exporter: v0.15.1
- Alertmanager: v0.11.0
- Apache exporter: v0.5.0
- Blackbox exporter: v0.11.0
ダウンロード
公式から提供されている、Prometheus, Node exporter, Alertmanager, Blackbox exporterのバイナリファイルをダウンロードします(ダウンロードページはこちら)。
Apache exporter のバイナリファイルは、公式サイトの「EXPORTERS AND INTEGRATIONS -> Third-party exporters -> HTTP」から Apache exporter を辿り、Apache exporterのリリースページからダウンロードします。
次に、設定ファイルを用意する必要がありますが、設定ファイルは Prometheus, Alertmanager, Blackbox exporter のみでOKです。
Prometheus の設定
Prometheus には、監視対象の設定、監視方法の設定、アラートの設定が必要です。
今回は Prometheus のバイナリファイルと同階層に次の2つのファイルを作成します。
- alert_rules.yml:alert push する条件の設定
- prometheus.yml(※):監視対象、監視方法、alert push の設定
※ダウンロード時にディレクトリに含まれている prometheus.yml のファイルは使わないので、適当に名前を変更しておいてください
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
groups: - name: node_exporter rules: # alert: アラート名 - alert: InstanceDown # expr: alert push の閾値 # インスタンスダウン (今回の設定では node_exporter, apache_exporter, blackbox_exporter が # 起動されていないことと同値) を条件にしています expr: up == 0 # for: alert push の expr の時間。 # インスタンスダウンした状態が 5 分間続いた時に、alert push されます for: 5m labels: severity: critical # annotations: アラートの通知内容 annotations: summary: "Instance {{ $labels.instance }} down" description: "{{ $labels.instance }} has been down for more than 5 minutes." - alert: cpu_used # CPU 使用率が 90% を超えた時を条件にしています expr: 100 * (1 - avg(rate(node_cpu{job='node',mode='idle'}[5m])) BY (instance)) > 90 for: 5m labels: severity: critical annotations: summary: "cpu {{ $labels.instance }} used over 90%" description: "cpu of {{ $labels.instance }} has been used over 90% for more than 5 minutes." - alert: memory_used # メモリ使用量が 90% を超えた時を条件にしています expr: 100 * (1 - node_memory_MemFree{job='node'} / node_memory_MemTotal{job='node'}) > 90 for: 5m labels: severity: critical annotations: summary: "memory {{ $labels.instance }} used over 90%" description: "memory of {{ $labels.instance }} has been used over 90% for more than 5 minutes." # アラートのグループは複数指定できます - name: apache_exporter rules: - alert: apache_workers # この設定では Apache の worker プロセスが 30 を超えた時を条件にしています expr: apache_workers{job="apache",state="busy"} > 30 for: 5m labels: severity: critical annotations: summary: "apache {{ $labels.instance }} workers over 30" description: "apache server {{ $labels.instance }} has been used over 30 workers for more than 5 minutes." - name: blackbox_exporter rules: - alert: http_status_200 # この設定では返ってきた http ステータスコードが 200 以外の時を条件にしています(外形監視) expr: probe_http_status_code{job='http_200'} != 200 for: 10s labels: severity: critical annotations: summary: "{{ $labels.instance }}: http request not return 200" description: "{{ $labels.instance }} http request not return 200 for more than 10 seconds." |
expr で指定するアラートの条件は、公式サイトに記載してある関数 や演算子を用いて設定します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
global: # scrape_interval: Prometheusがexporterなどに情報を取りに行く間隔 # 今回は Prometheus が 各種 exporter に対して情報を 15 秒間隔で取りに行きます scrape_interval: 15s # evaluation_interval: ルールの評価を行う間隔 # 今回のルールファイルは alert_rules.yml になります evaluation_interval: 15s alerting: alertmanagers: - static_configs: # targets: alert push する対象 # 今回はローカルの AlertManager (ポート番号:9093) に対して push します - targets: - 'localhost:9093' # prometheus が取得した情報を評価するルールの設定ファイルのパス rule_files: - "alert_rules.yml" # 監視対象の設定 scrape_configs: - job_name: 'node' static_configs: # targets: Prometheus が情報を pull する対象のホスト名もしくはIPアドレスと、ポート番号を設定 # ここでは node_exporter (ポート番号:9100) を指定しています - targets: - 'example.com:9100' - job_name: 'apache' static_configs: # targets: Prometheus が情報を pull する対象のホスト名もしくはIPアドレスと、ポート番号を設定 # ここでは apache_exporter (ポート番号:9117) を指定しています - targets: - 'example.com:9117' - job_name: 'http_200' metrics_path: /probe params: # 今回は http アクセスをするので、 http_2xx を指定しています module: ['http_2xx'] static_configs: # 監視対象のサービスのURLを指定 - targets: - 'http://example.com' relabel_configs: - source_labels: [__address__] target_label: __param_target - source_labels: [__param_target] target_label: instance - target_label: __address__ # Prometheus が情報を pull 対象のホスト名もしくはIPアドレスと、ポート番号を設定 # ここでは ローカルの blackbox_exporter (ポート番号:9115) を指定しています replacement: localhost:9115 |
Alertmanager の設定
Alertmanager では以下の内容を設定する必要があります。
- アラートするツール、アラート先
- アラートのグループ化
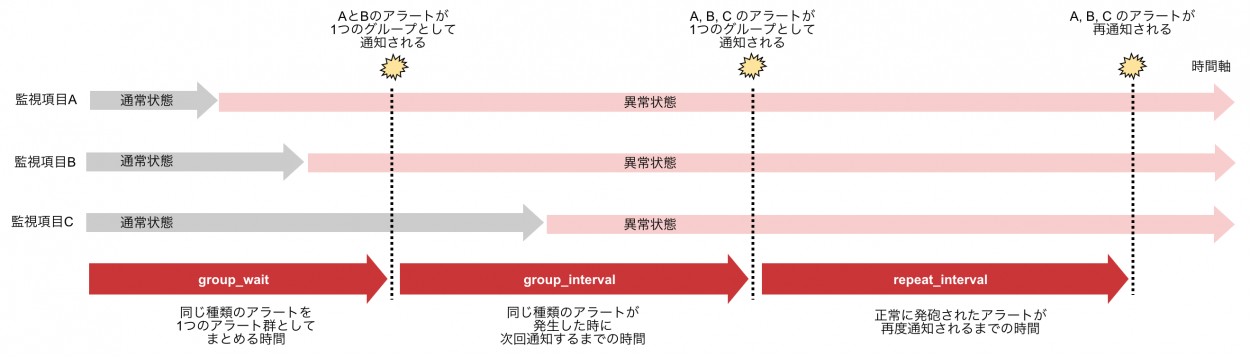
Prometheus のアラートには、類似したアラートを1つにまとめるグループ化の概念があります。
https://prometheus.io/docs/alerting/alertmanager/#grouping
Grouping categorizes alerts of similar nature into a single notification. This is especially useful during larger outages when many systems fail at once and hundreds to thousands of alerts may be firing simultaneously.
ユーザーにとって無駄な通知を省くため、Prometheus のアラートでは、同じ種類のアラートは一つにまとめて通知するのが良いとされています。
今回はメールと Slack 宛に通知を送るよう設定してみます。
Alertmanager のバイナリファイルと同階層に設定ファイル alert.yml を以下のように作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
global: # Slack の webhook URL の指定 slack_api_url: 'https://hooks.slack.com/************' # SMTP 接続先 smtp_smarthost: 'localhost:25' smtp_require_tls: false # アラート通知主の指定 route: # receiver: ルート名の指定 receiver: 'test-route' # group_by: アラートを同じ種類とみなす条件 # この場合、アラート名で判定されます group_by: [alertname] # group_wait: 同じ種類のアラートを1つのアラート群としてにまとめる時間 group_wait: 10s # group_interval: 同じ種類のアラートが発生した時に次回通知するまでの時間 group_interval: 5m # repeat_interval:正常に発砲されたアラートが再度通知されるまでの時間 repeat_interval: 1h receivers: - name: 'test-route' slack_configs: # Slack のチャンネル名の指定 - channel: '#alert_test' email_configs: # メールの宛先 |
アラートのグループ化の定義について、文だけでは理解しにくいので、図にしました。
Blackbox exporter の設定
Blackbox exporter では外形監視の方法を設定します。
Blackbox exporter のバイナリファイルと同階層に設定ファイル blackbox.yml(※) を作成します。
ここでは、http を使ってサービスを監視する設定を行なっています。
※ダウンロード時にディレクトリに含まれている blackbox.yml のファイルは使わないので、適当に名前を変更しておいてください
|
1 2 3 4 5 6 7 8 |
modules: http_2xx: # prober: プロトコルの指定 prober: http http: # method: httpメソッドの指定 # GET でアクセスしてサービス監視を行います method: GET |
Apache の設定
Apache exporter はデフォルトでは http://localhost/server-status/?auto にアクセスして、Apache の活動状況を取得します。
https://github.com/Lusitaniae/apache_exporter#apache-exporter-for-prometheus-
-scrape_uri string
URI to apache stub status page. (default "http://localhost/server-status/?auto")
Apache exporter 自身の設定は必要ありませんが、活動状況を取得できるように Apache に mod_status を設定する必要があります。
起動
監視対象のサーバーで、Node exporter, Apache exporter を起動します。
|
1 2 3 4 5 |
# Node exporter の起動 (バイナリファイル node_exporter があるところで実行) ./node_exporter # Apache exporter の起動 (バイナリファイル apache_exporter があるところで実行) ./apache_exporter |
ローカルサーバーで Prometheus, Alertmanager, Blackbox exporter を起動します。
|
1 2 3 4 5 6 7 8 |
# Alertmanager の起動 (バイナリファイル alertmanager があるところで実行) ./alertmanager -config.file=alert.yml # Blackbox exporter の起動 (blackbox_exporter のバイナリファイルがあるところで実行) ./blackbox_exporter --config.file=blackbox.yml # Prometheus の起動 (バイナリファイル prometheus があるところで実行) ./prometheus --config.file=prometheus.yml |
http://localhost:9090/targetsにアクセスすると、次のように監視対象が表示されます。
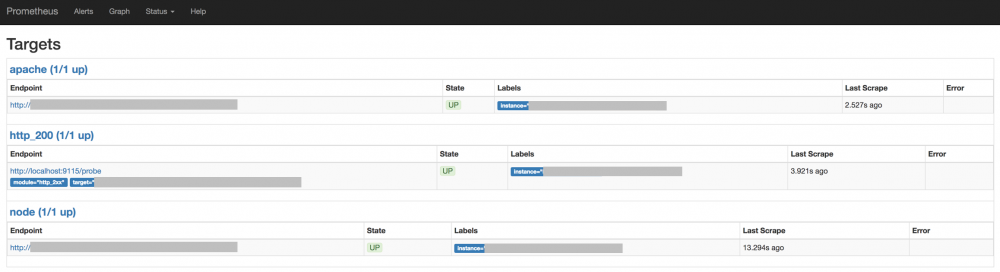
また、 Graph タグを表示し、メトリクスの評価式を入力した後に「Execute」を押すと、グラフが表示されます。
例として、CPU 使用率をグラフ化してみました。
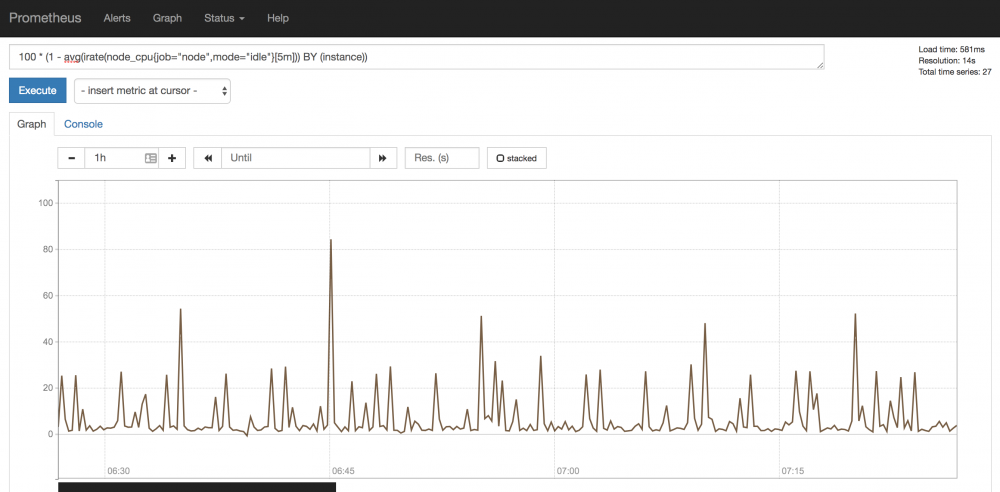
CPU使用率は評価式「100 * (1 - avg(irate(node_cpu{job='node',mode='idle'}[5m])) BY (instance))」で表示できます。
ここで使用する評価式の関数は、ルールファイル(alert_rules.yml)の expr に記述したものと同様のものになります。
ただし、ルールファイルでは条件式とするために不等号が入っていますが、ここでの評価式では不等号は不要です。
もし、CPU 使用率が 90% を超えた場合、次のようにメールと Slack に通知が来ます。
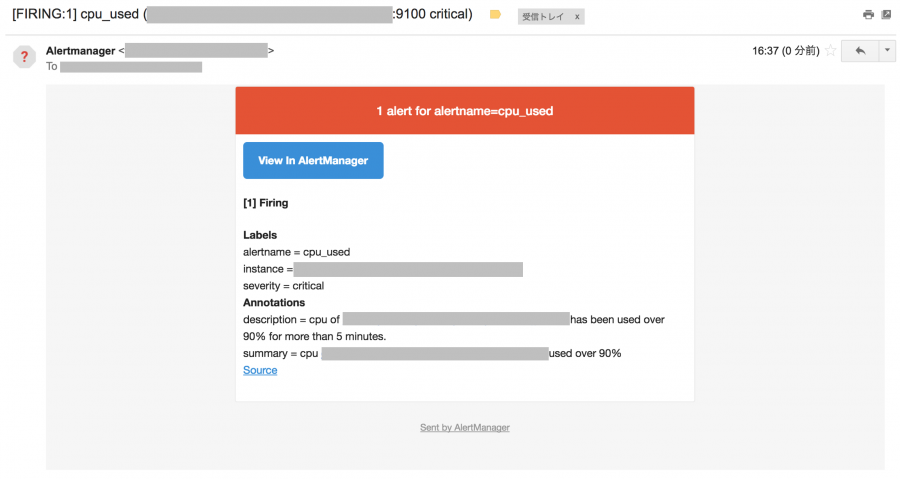

以上で、Prometheus の一通りの監視設定をすることができました。
まとめ
最近ホットな Prometheus 監視をまるっと設定してみました。
今回取り上げた内容は次の通りになります。
- Prometheus, Node exporter, Alertmanager, Apache exporter, Blackbox exporter のダウンロード
- Prometheus の設定
- alert push する条件の設定
- 監視対象、監視方法、alert push の設定
- Alertmanager の設定
- アラートするツール、アラート先、アラートのグループ化の設定
- Blackbox exporter の設定
- 外形監視の設定
- Apache exporter の設定
- mod_status の設定
- Prometheus, Node exporter, Alertmanager, Apache exporter, Blackbox exporter の起動
- CPU 使用率の簡単なグラフ化
これから Prometheus を使ってみようと思っている方に、少しでも参考にしていただければ幸いです。
最後まで読んでいただき、ありがとうございました。
